Discover Interlinking Opportunities Using K-Means and Python
It’s no mystery that interlinking is important for SEO. A big part of the interlinking strategy is knowing what should link to what. A quick first pass should be to look at what is high-level topically related and then you can get more granular after that.
One such strategy for this is to simply look at your existing content clusters or categories, but what if you don’t have a great site taxonomy? What if you have topics that span across multiple categories. It can be a mess trying to figure out at a high level what should link to what.
This short Python SEO script will save your day! By using a sentence-transformer with k-means and simple n-graming, we can in seconds cluster your site content using their page titles! These clusters give you a quick grouping of topically related pages for you to consider interlinking between. Let’s go!
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab.
- ScreamingFrog HTML crawl list or CSV with URLs (if not from ScreamingFrog either mirror the column names or make adjustments to the code below)
Install Modules
The main workhorse module we’re going to use is the sentence transformer from Huggingface and sbert. Remember if you are running in Google Colab to add an exclamation mark at the beginning.
pip3 install -U sentence-transformers
Import Modules and Model
- pandas: For importing the URL list and then storing the comparison results
- NLTK: NLP module handles the n-graming and word type tagging
- ngrams: functions for n-grams
- stopwords: contains a list of common stop words
- punkt: general extension for NLTK
- collections: for counting n-gram frequency
- string: for filtering out punctuation from the anchor text
- sentence_transformers: for sentence embeddings
- sklearn.cluster: machine learning module where we can access the k-means algorithm
Now let’s get these modules into our code!
import nltk
nltk.download('punkt')
from nltk.util import ngrams
from nltk.corpus import stopwords
nltk.download('stopwords')
from collections import Counter
import string
import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
Next, we load in the sentence transformer model. In the words of Huggingface: “This is a sentence-transformers model: It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for tasks like clustering or semantic search.” The training data used for the model was mostly from UGC platforms like Reddit, Yahoo Answers, citation databases, Stack Exchange and WikiAnswers.
embedder = SentenceTransformer('all-MiniLM-L6-v2')
Setup N-Gram and Data Cleaning Functions
Now we’ll create the function that sends the titles into the NLTK ngrams() function. This part is a scrappy method to categorize each cluster. Remember that k-means does not label. It simply groups based on similarity. To help get a handle on why clusters are what they are, we are attempting to name them by discovering the top n-gram for the cluster.
def extract_ngrams(data, num): n_grams = ngrams(nltk.word_tokenize(data), num) gram_list = [ ' '.join(grams) for grams in n_grams] return gram_list
We then call the above function as part of another function that focuses on data cleaning. We take the title list, join it all together into one big string and send it to our extract_ngrams() function. After the n-graming, we filter our stop words, punctuation, and lower case everything for standardization. Then we use the Counter() from Collections() to select the top n-gram by frequency. Note, in this tutorial we are processing for 1-gram. You can also get good results with 2-gram, but you’ll need to modify the data cleaning to handle it.
def getname(cluster):
data = ''
data = ' '.join(cluster)
keywords = extract_ngrams(data, 1)
stop_words = set(stopwords.words('english'))
cluster_name = [x.lower() for x in keywords]
cluster_name = [x for x in cluster_name if not x in stop_words]
cluster_name = [x for x in cluster_name if x not in string.punctuation]
cluster_name = list(Counter(cluster_name).most_common(1))
return cluster_name
Setup Dataframes and Title list data
It’s time to get this script running. We first create an empty dataframe that will be used to house the final cluster data. Then we load in our crawl CSV. You need an “Address” and a “Title 1” column which is standard in a ScreamingFrog internal HTML export.

Then we filter out any problem rows. This next step is to filter out branding from the title which will skew the algorithm. n this example below I cam filtering out “| Physics Forums” and “| PF Insights”. Edit according to your title structure. Don’t skip this step or your clusters will be less relevant. Finally, we send the title data to a list for processing later.
df2 = pd.DataFrame(columns = ['cluster', 'title', 'url'])
df = pd.read_csv("k-means.csv")
df.dropna(inplace=True)
df['Title 1'] = df['Title 1'].replace({' \| Physics Forums':'', ' \| PF Insights':''}, regex=True)
corpus = df["Title 1"].tolist()
df
Vectorize Titles and Cluster by K-Means
Now we get to the meat of the script where we send in our title information to the sentence transformer. The k-means algorithm requires choosing the number of clusters you want to force. Play with this number depending on the number of titles you have and or due to topical diversity. If you find there are many clusters with few results, reduce the number, if you find some clusters are too broad, increase the number. Most of the code in this next snippet is stock script from Huggingface.
corpus_embeddings = embedder.encode(corpus)
# adjust this as needed
num_clusters = 15
clustering_model = KMeans(n_clusters=num_clusters)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = [[] for i in range(num_clusters)]
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(corpus[sentence_id])
Find URLs and Store Data
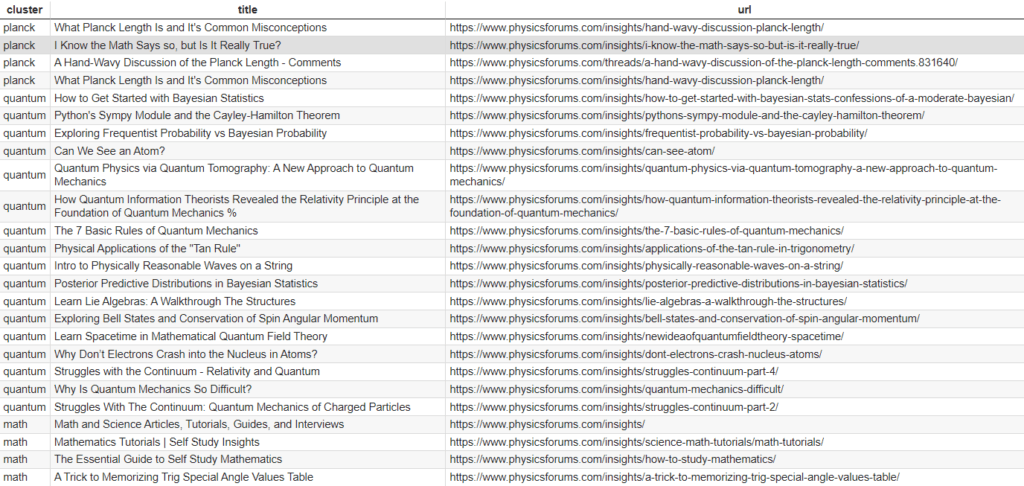
The cluster data is now in the list object clustered_sentences. It’s time to loop through that list. First, we want to call the getname() function we created earlier which n-grams the titles in the cluster in order to make an attempt at naming the cluster. Then because the clusters only are titles, we need to grab the corresponding URL found back in the original dataframe. Once we have the cluster name, the title, and the URL, we store it in the empty dataframe we created earlier. That’s it, see the example output below! Note, it’s just a small sample of the actual output. Remember, there are as many cluster names as there are clusters that you set the number for earlier.
for i, cluster in enumerate(clustered_sentences):
cluster_name = getname(cluster)
for x in cluster:
geturl = df[df['Title 1']==x]['Address'].values[0]
getdict = {'cluster':cluster_name[0][0],'title':x,'url':geturl}
df2 = df2.append(getdict, ignore_index = True)
df2
Output
Conclusion
Large and not tightly categorized sites are really difficult to find interlinking opportunities for SEO. With the above framework, you are now able to find opportunities by clustering your site’s content using k-means and sentence transformers. This can work great for very large sites!
Remember to try and make my code even more efficient and extend it into ways I never thought of! Now get out there and try it out! Follow me on Twitter and let me know your SEO applications and ideas!
K-Means Interlinking FAQ

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024