Scraping YouTube Video Pages for SEO with Python
I had a project this week that tasked my team with optimizing YouTube tags for a couple hundred videos. We could do it manually but thought this was a nice chance to use Python. Our idea was we could scrape YouTube video page information, put it into a spreadsheet for easier organization and identification of optimization needs in terms of tagging. It turns out to be easier than I thought outside of keeping Google’s blocking tendencies at bay.
In this Python SEO tutorial, I’ll show you how to scrape the title, views, description, and tags for a video. The bonus is we’ll detect if any tags are used in the description.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab.
- Video URL list CSV file with a URL column labeled “urls”
- I was able to quickly scrape all the videos in a channel via a Firefox/Chrome extension called LinkGopher.
Import Modules
- pandas: for importing the URL CSV file, storing and exporting results
- fake_useragent : generates user_agents to evade Google blocking
- bs4: an HTML parser
- requests: makes the HTTP call
- time: delaying the script to evade Google blocking
- re: for regex matching
- numpy: for randomization function
Before we begin, remember to watch the indents of anything you copy here as sometimes the code snippets don’t copy perfectly. First, we need to install fake_useragent. If you are using Google Colab put an exclamation market at the start.
pip3 install fake_useragent
Let’s first import the modules needed for this script expressed above.
from fake_useragent import UserAgent from bs4 import BeautifulSoup import requests import pandas as pd import time import re import numpy as np
Create Scraping Function
We’re going to start with creating a function that handles the scraping of each video page. We will be sending in the URL data, user agent object, and the crawl delay number. We now set the user agent in the header using the random function for the user agent module. This will randomize the user agent details like OS and browser. Next, we set the random delay time which we calculate later. A random script delay is essential for evading Google’s blocking tendencies.
def get_youtube_info(url,ua,crawl_delay):
header = {"user-agent": ua.random}
time.sleep(crawl_delay)
Now we make the HTTP request using the url and header variables we set above. Then we create a BeautifulSoup object using the content from the video page. We then use the find_all() function of BeautifulSoup to put all the open graph meta tags with the property “og:video:tag” into a Python list. Then we use the find() function to get the text within the title tag.
request = requests.get(url,headers=header,verify=True)
soup = BeautifulSoup(request.content,"html.parser")
tags = soup.find_all("meta",property="og:video:tag")
titles = soup.find("title").text
Now we will attempt to get the video description content. YouTube pages are mostly rendered via Javascript, so you can’t easily search for the tags that end up rendered. When you make an HTTP request via Python the result is not rendered. It’s just the raw code. So to get the description contained in the Javascript we’ll need to use a little RegEx and afterward do a little cleanup. I also found that some videos didn’t have a description at all and ended up creating an error. So for that, we use a try/exception.
try:
getdesc = re.search('description\":{\"simpleText\":\".*\"',request.text)
desc = getdesc.group(0)
desc = desc.replace('description":{"simpleText":"','')
desc = desc.replace('"','')
desc = desc.replace('\n','')
except:
desc = "n/a"
Next, we do a little more RegEx to find the date and view data. Then we return the data we scraped back to the main script.
getdate = re.search('[a-zA-z]{3}\s[0-9]{1,2},\s[0-9]{4}',request.text)
vid_date = getdate.group(0)
getviews = re.search('[0-9,]+\sviews',request.text)
vid_views = getdate.group(0)
return tags,titles,vid_date,desc,views
Create Tag Match Function
The next phase is comparing the tag list to the description content and seeing what tags are in that content. One could imagine if there aren’t many matches that is an opportunity to fix. For this, we create a new function that accepts the description text and the tag list. At this point, our tag list is a comma delineated list and you’ll find out why later on, but for this function, we need to turn it back into a Python list, so we use split(). Then we loop through each tag in the list and use the string function find() which looks for the tag in the description. If the result is not “-1”, then we know there was a match and we add it to the matches list variable.
def tag_matches(desc, vid_tag_list):
vid_tag_list = vid_tag_list.split(',')
matches = ""
for x in vid_tag_list:
if (desc.find(x) != -1):
matches += x + ","
return matches
Import Data, Set Up Variables and Call Functions
Above we created the two main functions of the script. Now we actually start at the beginning. We first load the videos CSV containing the video URLs and convert the column into a list so we can easily loop through them.
df = pd.read_csv("videos.csv")
urls_list = df['urls'].to_list()
Next, we create our user agent function that we access and randomize in the YouTube scraper function above. Then we create our delay list. This list comprehension creates a list containing numbers ordered from 10 to 22, incrementing by 1 digit. Later on, we’ll use Numpy to randomly select from that list. I’ve found this ranged list to evade Google pretty well. Choose a digit less than 10 and you start getting blocked more often. Lastly, we create our empty dataframe which we’ll eventually store our scraped data.
ua = UserAgent() delays = [*range(10,22,1)] df2 = pd.DataFrame(columns = ['URL', 'Title', 'Date', 'Views','Tags', 'Tag Matches in Desc'])
Now we want to loop through our URL list and start processing the pages and content. crawl_delay is set for each URL by using the np.random.choice() function to randomly select a value from the list. One URL might have a delay of 13, the next it may be 19. This denies any pattern Google could detect and looks more like a human.
for x in urls_list:
crawl_delay = np.random.choice(delays)
vid_tags,title,vid_date,desc,views = get_youtube_info(x,ua,crawl_delay)
vid_tag_list = ""
for i in vid_tags:
vid_tag_list += i['content'] + ", "
Below is where we call the function to evaluate the tag to description matching. Then we clean up the page titles as YouTube adds their brand and that is unnecessary to include in our data. Once we’re done scraping and tag matching we fill out a dictionary and append it to the empty dataframe we added earlier. Lastly, we export the dataframe as a CSV for you to do further analysis.
matches = tag_matches(desc,vid_tag_list)
title = title.replace(' - YouTube','')
dict1 = {'URL':x,'Title':title,'Date':vid_date,'Views':views,'Tags':vid_tag_list,'Tag Matches in Desc':matches}
df2 = df2.append(dict1, ignore_index=True)
df2.to_csv("vid-list.csv")
Output
Note this dataframe example below is from my work’s YouTube channel with 2 videos :)
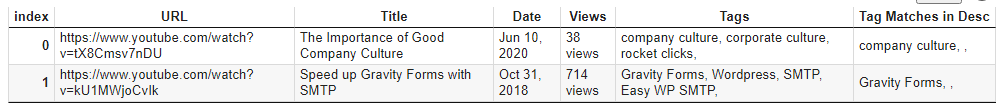
Conclusion
So there you have it! You can now scrape YouTube pages to help with your optimization efforts. With this framework, you can extend it in so many interesting directions. Now get out there and try it out! Follow me on Twitter and let me know your applications and ideas!
YouTube Scraping FAQ
How can Python be utilized to scrape YouTube video pages for SEO purposes?
Python scripts can be developed to scrape data from YouTube video pages, extracting valuable information such as video titles, descriptions, tags, and view counts for SEO analysis.
Which Python libraries are commonly used for scraping YouTube video pages?
The requests library is often employed for making HTTP requests, and BeautifulSoup or lxml are commonly used for parsing HTML content when scraping YouTube video pages with Python.
What specific data can be extracted from YouTube video pages for SEO analysis using Python?
Python scripts can extract data such as video titles, descriptions, upload dates, view counts, and tags. This information is valuable for SEO professionals in understanding the performance and relevance of YouTube videos.
Are there any considerations or limitations when scraping YouTube video pages for SEO with Python?
Consider YouTube’s terms of service, ethical web scraping practices, and potential changes in the HTML structure. Use APIs when available, and ensure compliance with YouTube’s policies.
Where can I find examples and documentation for scraping YouTube video pages with Python?
Explore online tutorials, documentation for web scraping libraries like BeautifulSoup, and resources specific to YouTube API interactions for practical examples and detailed guides on scraping YouTube video pages for SEO using Python.

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024