Evaluate Sentiment Analysis in Bulk with spaCy and Python
Sentiment analysis is about evaluating text for positive or negative views and feelings. many times sentiment is expressed using verbs like sad, mad, happy, and excited, but we can expand that sentiment understanding to a vast host of other parts of speech using machine learning.
I’m not going to try and pull one over on you with this one. There is little doubt sentiment analysis for SEO is an edge tactic. Sentiment analysis is not the first or second or even 10th thing you should be thinking of spending time on in regards to SEO. However, in certain circumstances, it can be very helpful and rewarding, such as:
- Your site writes reviews or opinion pieces.
- You have a comment or review system.
- You’re in an industry that expects a certain attitude.
- You’ve tried everything else and your competition is still beating you.
In this SEO guide, we’re going to go step by step in showing you how to use the machine learning NLP Python module spaCy to evaluate the sentiment of textual content on any URLs you want. We’ll spit out the score, label it as positive or negative and then list out the words that were detected as either-or.
Table of Contents
Key Points
- Sentiment analysis is about evaluating text for positive or negative views and feelings.
- Can be helpful and rewarding in certain circumstances, such as: reviews, comment or review systems, or when in an industry that expects a certain attitude.
- Demonstrates how to use the machine learning NLP Python module spaCy to evaluate the sentiment of textual content on any URLs.
- Requirements: Python 3, Linux installation or Google Colab, and list of URLs in a single column with a header of ‘url’.
- Install the spaCy and spacytextblob modules and download the English trained pipeline.
- Load the CSV that contains URL list, convert those URLs into a list and set some empty lists which will store data.
- Use requests module and BeautifulSoup to get HTML from URL, extract text from between any HTML tags and remove some whitespaces.
- Load the page text into spaCy’s nlp() function, extract and round the sentiment score from the blob attribute, and label as positive or negative.
- Parse out which words in the page text were detected as either negative or positive.
- Add 4 lists to original dataframe and print it out.
- Extend code into ways never thought of.
Note: you can also read my guide on using Google NLP for sentiment analysis. That guide shows you how to create these fun little plots (this is also possible with spaCy and this tutorial but this tutorial is focused on bulk analysis and these plots are good for hundreds of evaluations).

Requirements and Assumptions
- Python 3 is installed and basic Python syntax is understood.
- Access to a Linux installation (I recommend Ubuntu) or Google Colab.
- List of URLs in a single column with a header of ‘url’.
Install Modules
First, we’ll make sure pandas is updated, install the spaCy and spacytextblob modules and download the English trained pipeline. As always if you are using Google Colab, include an exclamation mark at the beginning of each install snippet.
pip3 install pandas==1.3.5 pip3 install spacy==3.2.0 pip3 install spacytextblob python3 -m spacy download en_core_web_sm
Import Modules
- spacy: NLP and machine learning module that will act as the backbone for the processing
- SpacyTextBlob: Helps spacy perform the sentiment analysis
- pandas: stores the data into a dataframe table
- BeautifulSoup: for scraping the content of the URLs
- requests: makes the connection to the URL
import spacy from spacytextblob.spacytextblob import SpacyTextBlob import pandas as pd from bs4 import BeautifulSoup import requests
Load NLP Pipeline
First, we’ll load the trained NLP pipeline en_core_web_sm into spaCy and then load spacytextblob which is another pipeline for sentiment analysis.
nlp = spacy.load('en_core_web_sm')
nlp.add_pipe('spacytextblob')
Load URL Data
Now let’s load in the CSV that contains your URL list. This should be a single column CSV with the header “Address”. We then convert those URLs into a list and set some empty lists which will store our data.
df = pd.read_csv("urls.csv")
urls = df["Address"].tolist()
url_sent_score = []
url_sent_label = []
total_pos = []
total_neg = []
Scrape URLs for Text Content
Next, we iterate through that URL list and process them one by one in the following manner:
- Get the HTML from the URL by using the requests module and setting a user-agent to help with bot blocking.
- Sending the HTML to BeautifulSoup for parsing.
- Remove any content between tags that we don’t want to process. Feel free to add more as needed. We only want relevant contextual content for that page.
- Get the text from between any HTML tags and remove some whitespaces.
- Remove any empty lines in the content chunk.
for count, x in enumerate(urls):
url = x
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
res = requests.get(url,headers=headers)
html_page = res.text
soup = BeautifulSoup(html_page, 'html.parser')
for script in soup(["script", "style","meta","label","header","footer"]):
script.decompose()
page_text = (soup.get_text()).lower()
page_text = page_text.strip().replace(" ","")
page_text = "".join([s for s in page_text.splitlines(True) if s.strip("\r\n")])
Process Sentiment of Content
Staying within the same loop, it’s time for the sentiment analysis now that we have our cleaned page text. Mind you the code formatting is a bit broken. Everything below should be indented with the loop above.
- Load the page text into spaCy’s nlp() function.
- Extract and round the sentiment score from the blob attribute which spaCy calls polarity.
- Construct a conditional evaluation of the sentiment score for labeling. You may want to play with the ranges and or add a neutral label for anything near 0.
- Add the label (positive or negative) and score to each respective list for future use. Scores will range from -1 to 1 (most negative to most positive).
doc = nlp(page_text) sentiment = doc._.blob.polarity sentiment = round(sentiment,2) if sentiment > 0: sent_label = "Positive" else: sent_label = "Negative" url_sent_label.append(sent_label) url_sent_score.append(sentiment)
Evaluate and Label Sentiment Score
We now have the sentiment score and sentiment label for each URL. It’s time to parse out which words in the page text were detected as either negative or positive.
- Create our empty container lists to store each URL’s detected words.
- Loop through doc._.blob.sentiment_assessments.assessments which is a tuple object consisting of the word, the polarity (sentiment score), and subjectivity. You can learn about using the subjectivity score here if important to you.
- Evaluate the second item in the tuple which is the score. Then depending on if positive or negative, select the first item in the tuple which is the word, and store it in the respective list.
- Once all the detected words are evaluated join them all into a comma delineated string. We also remove duplicates using the set() function.
positive_words = []
negative_words = []
for x in doc._.blob.sentiment_assessments.assessments:
if x[1] > 0:
positive_words.append(x[0][0])
elif x[1] < 0:
negative_words.append(x[0][0])
else:
pass
total_pos.append(', '.join(set(positive_words)))
total_neg.append(', '.join(set(negative_words)))
Attach to Dataframe and Display/Export
Last but not least we add our 4 lists to our original dataframe and print it out. Note that below this should have no indentation as it’s out of the loop.
df["Sentiment Score"] = url_sent_score
df["Sentiment Label"] = url_sent_label
df["Positive Words"] = total_pos
df["Negative Words"] = total_neg
#optional export to CSV
#df.to_csv("sentiment.csv")
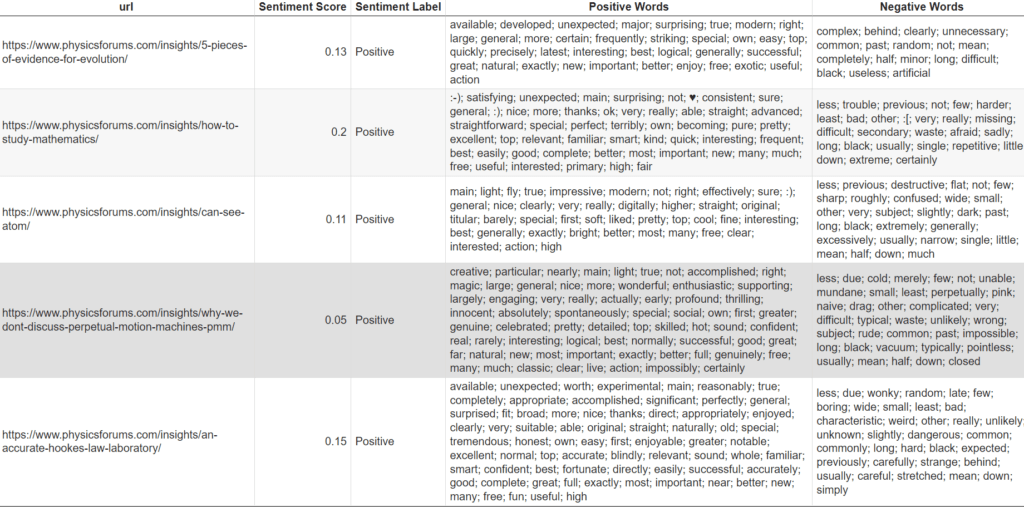
df
Output
Conclusion
That’s all there is to it! You now have the framework for analyzing sentiment across you any URLs you want or for any text you want. If you don’t want to evaluate pages and have chucks of text like reviews or comments, simply remove the URL scraping and inject whatever text you want into the page_text variable.
Remember to try and make my code even more efficient and extend it into ways I never thought of! Now get out there and try it out! Follow me on Twitter and let me know your SEO applications and ideas for sentiment analysis!
Sentiment Analysis FAQ
What is sentiment analysis?
Sentiment Analysis is a type of Natural Language Processing (NLP) that evaluates text for positive or negative views and feelings. This can be done using machine learning and specialized NLP libraries, such as spaCy and SpacyTextBlob, to interpret sentiment in textual content.
What are some applications of sentiment analysis?
Sentiment Analysis is often used in SEO to evaluate reviews and opinion pieces. It can also be used to assess a certain attitude in an industry, or to gain an edge over competitors.
What are the requirements for sentiment analysis?
To perform sentiment analysis, you need a basic understanding of Python syntax, access to a Linux installation or Google Colab, and a list of URLs in a single column with a header of ‘url’.
How does sentiment analysis work?
Sentiment analysis works by scraping the content of URLs for text content, processing sentiment, evaluating and labeling the sentiment score, attaching the results to a dataframe and displaying or exporting the output.

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024
Related Python Tutorials
- Scraping YouTube Video Page Metadata with Python for SEO

- Use Python to Label Query Intent, Entities and Keyword Count

- Automatically Find SEO Interlinking Opportunities with Python
- Use Google NLP to Compare Two Web Page’s Entities Using Python

- Find Keyword Opportunities with Google Trends, Python and Ahrefs