
Calculate SERP Rank Readability Scores Using Python
Readability scores are not a verified SEO ranking factor. That said, you should still care: if your content doesn’t match your audience’s reading level, you may see higher bounce rates, lower engagement, and fewer conversions. Your audience expects content written appropriately for the subject matter; when your content meets those expectations, better results follow.
In this tutorial, I’ll show you step-by-step how to calculate your SERP competitors’ reading level (as well as reading time and word count). This lets you compare competitors’ scores to your own; but first, let’s chat about the Flesch–Kincaid readability algorithm which we’ll be using. Note there are dozens of other algorithms, Flesch-Kincaid happens to be one of the more commonly used. Also note, Screamingfrog can do the readability calculation easily during a crawl, but hey, that costs money, this script is free.
A readability algorithm known as the Flesch–Kincaid Grade Level uses an algorithm that evaluates the level of complexity based on the average number of words per sentence and the average number of syllables per word to provide a result that ranges from 0 to 18. A score of 18 represents text which is the most difficult to comprehend. It was developed by the US Navy to measure the amount of education someone would have to have to comprehend a piece of writing. The higher the number the easier it would be to read and a lower number would mean that many people may struggle.
| Score | School level (US) | Notes |
|---|---|---|
| 100.00–90.00 | 5th grade | Very easy to read. Easily understood by an average 11-year-old student. |
| 90.0–80.0 | 6th grade | Easy to read. Conversational English for consumers. |
| 80.0–70.0 | 7th grade | Fairly easy to read. |
| 70.0–60.0 | 8th & 9th grade | Plain English. Easily understood by 13- to 15-year-old students. |
| 60.0–50.0 | 10th to 12th grade | Fairly difficult to read. |
| 50.0–30.0 | College | Difficult to read. |
| 30.0–10.0 | College graduate | Very difficult to read. Best understood by university graduates. |
| 10.0–0.0 | Professional | Extremely difficult to read. Best understood by university graduates. |
* source wikipedia
Important: A higher or lower number doesn’t indicate performance—neither is inherently better. It all depends on your audience. If your content covers theoretical physics, a lower score may be acceptable. If you’re teaching 8-year-olds about trees, a higher score is likely better.
Now that you have the necessary background, let’s dive into the script!
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax is understood
- Some SERP scraper like SerpAPI or ValueSERP
- Access to a Linux installation (I recommend Ubuntu) or Google Colab
- Be careful with copying the code as indents are not always preserved well
- A limitation of the script is that it won’t be able to scrape URLs that are JavaScript rendered. These URLs will output extremely low word counts. This usually affects about 10% of SERPs.
Install and Import Modules
Listed below are the modules we’ll be using in this script:
- google-search-results: for calling SERPAPI to scrape the SERP
- textstat: this includes the Flesch-Kincaid readability algorithm
- bs4: to help scrape URL content
- requests: for connecting to URLs and APIs
- pandas: for storing the data
- statistics: for calculating the median
- json: for processing the return data from the SerpAPI
Let’s start by installing the SerpAPI, textstat, and bs4 modules. If you’re using a notebook, include an exclamation mark at the beginning of each install command.
pip3 install google-search-results pip3 install textstat pip3 install bs4
Now we import the libraries we’ll need to start the script. Each use is listed above.
import requests import textstat from bs4 import BeautifulSoup import pandas as pd from serpapi import GoogleSearch import json from statistics import median
Create SERPAPI Function
Next, we’ll create the basic function for calling SerpApi. It takes in the query, the number of results requested, and your API key. Adjust the parameters as you need. Be sure to reference their docs here. If you use a different SERP scraper like ValueSERP, adjust this function according to its API.
def serp(query, num_results, api_key):
params = {
"q": query,
"location": "United States",
"hl": "en",
"gl": "us",
"google_domain": "google.com",
"device": "desktop",
"num": num_results,
"api_key": api_key}
search = GoogleSearch(params)
results = search.get_dict()
return results
Create SERP URL Scraper
Next is the function that takes in the response from SerpAPI. The response contains all the SERP details for the query in JSON format. We loop over the organic results and store each URL in a Python list for later. If the mydomain variable, which represents your site, is found, we’ll store it separately.
def get_serp_comp(results, mydomain):
serp_links = []
mydomain _url = "n/a"
mydomain _rank = "n/a"
for count, x in enumerate(results["organic_results"], start=1):
serp_links.append(x["link"])
if mydomain in x["link"]:
mydomain _url = x["link"]
mydomain _rank = count
return serp_links, mydomain_url, mydomain_rank
Process URL Content and Calculate Readability
The next part is a large function that I will break down using an ordered list of what is happening. It takes the SERP URL list, scrapes competitor pages, and calculates the readability score.
- Create lists to store our data and a few default values, plus the headers variable used when we scrape sites.
- Loop through the SERP links we found earlier.
- Scrape each URL’s content, filtering out common boilerplate areas.
- Call the textstat module with the page text to return the readability score.
- Store the rounded readability score, calculate reading time in minutes (divide seconds by 60), and assume 25 ms per character for default reading speed.
- Calculate and store the word count.
- If the page belongs to you, mark it and record its readability metrics.
- After looping, calculate median reading levels, reading times, and word counts across the set.
def get_reading_level(serp_links,mydomain):
reading_levels = []
reading_times = []
word_counts = []
mydomain_reading_level= "n/a"
mydomain_reading_time= "n/a"
mydomain_word_count= "n/a"
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
for x in serp_links:
res = requests.get(x,headers=headers)
html_page = res.text
soup = BeautifulSoup(html_page, 'html.parser')
for tag in soup(["script", "noscript","nav","style","input","meta","label","header","footer","aside",'head']):
tag.decompose()
page_text = (soup.get_text()).lower()
reading_level = int(round(textstat.flesch_reading_ease(page_text)))
reading_levels.append(reading_level)
reading_time = textstat.reading_time(page_text, ms_per_char=25)
reading_times.append(round(reading_time/60))
word_count = textstat.lexicon_count(page_text, removepunct=True)
word_counts.append(word_count)
if mydomain in x:
mydomain_reading_level = int(round(reading_level))
mydomain_reading_time = round(reading_time/60)
mydomain_word_count = word_count
reading_levels_mean = median(reading_levels)
reading_times_mean = median(reading_times)
word_counts_median = median(word_counts)
return reading_levels, reading_times, word_counts, reading_levels_mean, reading_times_mean, word_counts_median, mydomain_reading_level, mydomain_reading_time, mydomain_word_count
Initiate the Functions
This is where the script starts: set a keyword for the query to analyze. num_results is how many SERP positions to return. The mydomain variable identifies your site—enter just the root domain without “www”. The serp function calls SerpAPI, get_serp_comp extracts the organic URLs, and get_reading_level scrapes those URLs to calculate reading levels, times, and word counts.
keyword = 'xbox specifications' num_results = 10 api_key = '' #add your serpapi key mydomain = '' #add just your root domain, no www results = serp(keyword,num_results,api_key) links, mydomain _url, mydomain _rank = get_serp_comp(results,mydomain) reading_levels, reading_times, word_counts, reading_levels_mean, reading_times_mean, word_counts_median, mydomain_reading_level, mydomain_reading_time, mydomain_word_count = get_reading_level(links,mydomain)
Output URL Data to Dataframe
Now we output all the calculated data into a dataframe. The style properties align table values to the left as a quality-of-life improvement.
df = pd.DataFrame(columns = ['url','reading ease','reading time (m)','word count'])
df['url'] = links
df['reading ease'] = reading_levels
df['reading time (m)'] = reading_times
df['word count'] = word_counts
df = df.style.set_properties(**{'text-align': 'left'})
df = df.set_table_styles(
[dict(selector = 'th', props=[('text-align', 'left')])])
df
Output Aggregate Data
Here I print the median metrics and compare them to your site. You could also store these aggregates in a dataframe if desired.
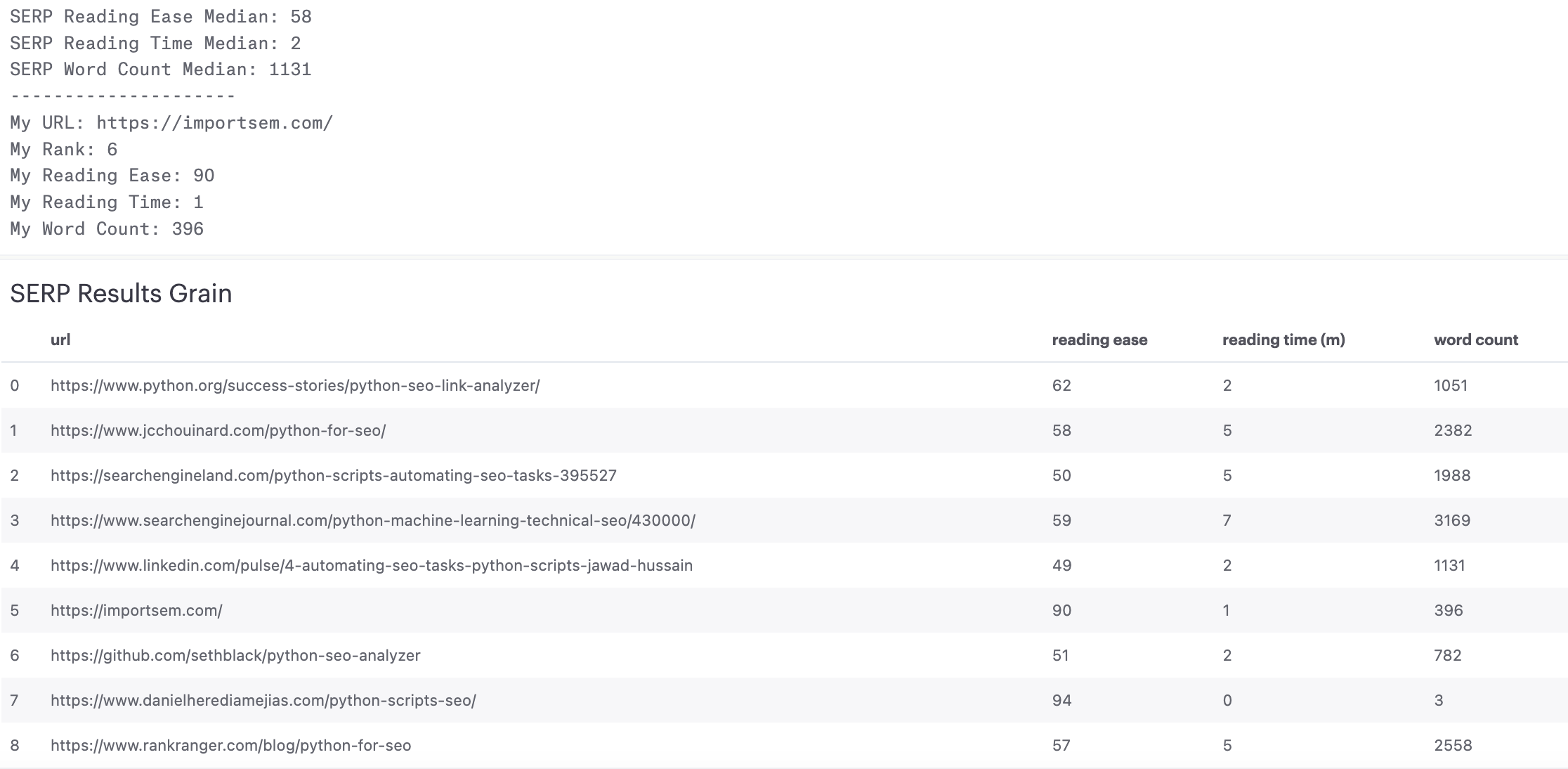
print("SERP Reading Ease Median: " + str(reading_levels_mean))
print("SERP Reading Time Median: " + str(reading_times_mean))
print("SERP Word Count Median: " + str(word_counts_median))
print("---------------------")
print("mydomain URL: " +str(mydomain_url))
print("mydomain Rank: " + str(mydomain_rank))
print("mydomain Reading Ease: " +str(mydomain_reading_level))
print("mydomain Reading Time: " + str(mydomain_reading_time))
print("mydomain Word Count: " + str(mydomain_word_count))
Example Output
Conclusion
Readability is an often-overlooked SEO consideration. Treat it as one of many factors to monitor rather than a single deciding metric. This process gives you a practical way to see how your content compares to the competition, though it doesn’t guarantee competitors are optimized. The point is to think about your audience and write in the way they’ll best receive. Keep extending and customizing these scripts to fit your needs—this is just the beginning.
Now get out there and try it out! Follow me on Twitter and let me know your Python SEO applications and ideas!
SERP Readability FAQ
How can Python be used to calculate SERP (Search Engine Results Page) rank readability scores?
Python scripts can fetch SERP data, extract page content, and calculate readability scores for each result, giving insights into the readability of top-ranking pages.
Which Python libraries are commonly used for calculating SERP rank readability scores?
Common libraries include requests for fetching pages, beautifulsoup for HTML parsing, and textstat (or other readability tools) for computing readability metrics.
What specific steps are involved in using Python to calculate SERP rank readability scores?
The typical steps are: fetch SERP results for target queries, extract and clean content from each result, apply readability analysis, and aggregate the scores for comparison.
Are there any considerations or limitations when using Python for this purpose?
Consider variability in SERP content, the choice of readability metric, and scraping limitations (for example, JavaScript-rendered pages). Also align measurements with your specific goals and update analyses over time.
Where can I find examples and documentation for calculating SERP rank readability scores with Python?
Check library documentation and online tutorials for examples—especially docs for the specific SERP scraper and readability libraries you choose.

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024











