Webpage Word Sense Disambiguation for SEO Using Python and NLTK
In semantics, ambiguity is partially defined as a word having multiple “senses”. A sense is a meaning or definition. Effective content in SEO should be as free of ambiguity as possible. When you have ambiguity in your content you risk machines (that evaluate your content via natural language understanding), not being able to understand your content or understand it inappropriately. If that occurs then the applied topical relevance for the page, a paragraph, or a sentence can be weak. To win at content SEO your content meaning must be clear and topically strong.
In this Python SEO tutorial, I’ll show you how to start analyzing your web content by using the Python NLP NLTK for word sense disambiguation. This method is not perfect, contains plenty of limitations, and still requires plenty of manual reviews. It is only the beginning of building a framework to help break down your content and for you to consider the meaning of content at a granular level.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab.
Import and Install Python Modules
- nltk: NLP module handles the n-graming and word type tagging
- pandas: for storing and displaying the results
- requests: for making HTTP call to URL
- bs4: for scraping the target URL’s content
Now let’s import all the modules as described above, into the script.
import nltk
from nltk.wsd import lesk
from nltk.corpus import stopwords
nltk.download('wordnet')
nltk.download('stopwords')
nltk.download("punkt")
nltk.download('averaged_perceptron_tagger')
import requests
from bs4 import BeautifulSoup
import pandas as pd
We start this off real simple, by creating the empty pandas dataframe which will ultimately contain our WSD analysis. It will contain each word (some filtering) in the URL’s content, the Sysnet (Lesk object), which is how the Lesk algorithm understands the word within its context, and then the definition of the Sysnet word. When you have the results, you’ll need to review the word compared to the Sysnet word. If there is a misalignment it’s a possible case where you need to clear up the ambiguity with more contextual support for the meaning you desire.
Setup Dataframe and Web Scraper
d = {'Word': [], 'Sysnet': [], 'Definition':[]}
df = pd.DataFrame(data=d)
Next, we need to grab the textual content from whatever URL you are looking to analyze. Edit the variable url. For this tutorial, we will analyze Stripe.com homepage. Then we grab the source code from that URL via requests.get(). Next, we use BeautifulSoup’s HTML parser to grab just the text from that URL.
url = "https://stripe.com/" res = requests.get(url) html_page = res.text soup = BeautifulSoup(html_page, 'html.parser') text = soup.find_all(text=True)
Text can be in a variety of places that we don’t want to analyze. Below is our blacklist of HTML tags where we don’t want to grab that text. Feel free to add/remove from that list with what your needs are. Lastly, we loop through that list using BeautifulSoup object we built before. In the end, we are left with a text string with only the content we want to analyze.
output = ''
blacklist = [
'[document]',
'noscript',
'header',
'html',
'meta',
'head',
'input',
'script',
'style',
'input',
'footer'
]
for t in text:
if t.parent.name not in blacklist:
output += t
Scraped Content Cleaning
The next step is a bunch of data cleaning and I’ll explain each step.
- We tokenize the content, which is just a term that means to put each word (1-gram) in the string discretely into a Python list.
- Lowercase each word and only put it back into the list if the token is alphanumeric. This removes punctuation.
- Add each word into a new list only if it doesn’t already exist in the list. This removes duplication. (this becomes a significant limitation in that you start to lose any kind of placement information. If you use a word twice, which is the ambiguous one? Requires more manual investigation in the end.)
- Build the stopword list for filtering
- Add each word into a new list only if the word doesn’t match with a word in the stopword list.
- Tag each word with a word type (noun, verb, adj). This will create a list of lists in the form of res2[word][word-type]
gram1 = nltk.word_tokenize(output)
gram1= [word.lower() for word in gram1 if word.isalnum()]
res = []
[res.append(x) for x in gram1 if x not in res]
stop_words = set(stopwords.words('english'))
res2 = []
[res2.append(x) for x in res if x not in stop_words]
res2 = nltk.pos_tag(res2)
Disambiguation with LESK Algorithm
We now have our list of words from the content of the URL of your choosing along with an attached word type. We need the word type in order to send that information to the LESK algorithm for greater word identification precision.
The last step here is to loop through each word in our res2 list and evaluate it for ambiguity in relation to the entire piece of content. You may in fact decide it’s better to evaluate a word by the sentence it’s in and feel free to adjust for that. After the start of the loop, we detect the word type and adjust the pos variable which we need to send to the LESK algorithm function. That is what tells the function what word type to expect. n = noun, v = verb, j = adjective, r = adverb and I = preposition (often an adverb).
We then build a Python dictionary object and use it to update our dataframe, which when we are finished looping, we display.
for x in res2:
try:
if 'N' in x[1]:
pos = 'n'
if 'V' in x[1]:
pos = 'v'
if 'J' in x[1]:
pos = 'a'
if 'R' in x[1]:
pos = 'r'
if 'I' in x[1]:
pos = 'r'
new_row = {"Word":x[0],"Sysnet":str(lesk(gram1,x[0],pos)),"Definition":str(lesk(gram1,x[0],pos).definition())}
df = df.append(new_row, ignore_index=True)
except:
pass
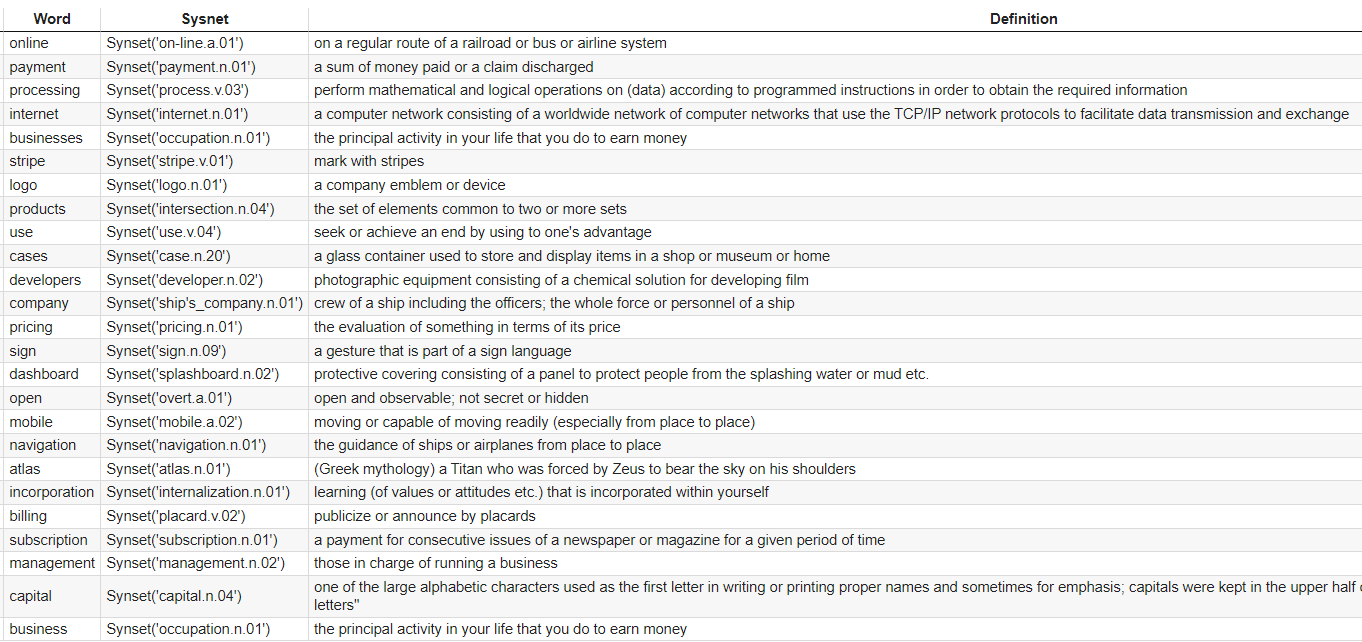
df
Output and Conclusion
We used the Stripe homepage for this tutorial and the output was 336 unique words. I have a snapshot of what the first 25 or so look like. There are 3 steps now for you to analyze.
- Compare the word with the Sysnet result. If they are different, it could be there is some confusion as to the meaning of the word that was intended by you.
- Compare the word with the Sysnet definition. Even if Sysnet returns the exact word or near-exact word, the definition could be different than what you intended.
- If a disconnect in meaning is found, look for where the word is used in the context of the page and determine if it’s a false-positive or if you can make adjustments to make the intent and meaning more clear. Avoid figures of speech and idioms as much as possible. Use plenty of support domain terms around terms often deemed ambiguous.
Now you have the start of a framework to begin understanding how machines could understand your textual content! Ambiguity is out, clarity is in!
Remember to try and make my code even more efficient and extend it into ways I never thought of! Now get out there and try it out! Follow me on Twitter and let me know your applications and ideas!
Word Sense Disambiguation FAQ

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024














