Use Python to Label Query Intent, Entities and Keyword Count
Query analysis is a large topic, but I wanted to focus on intent and entity recognition. Intent and entity recognition are very important concepts to understand in SEO. Google’s use of machine learning has rapidly increased since 2013 when they introduced their Knowledge Graph.
For intent, what is important is how Google’s understanding of the intent, matches the intent of the relevant page you want to rank for that query. If there is a mismatch, you’re unlikely to rise as high as you wanted in the rankings.
For entities, it’s about helping you know the words and concepts that Google explicitly understands in the queries that are helping people reach your site. If the analysis you find below surprises you or is a little off, you know Google might not be understanding your content as well as you thought.
To help you analyze intent and entities within your queries I’ll guide you step-by-step in this tutorial that will give you the framework to get you that understanding. Use this guide as a launch-off point to extend and optimize what I’ve already done. Don’t forget to check out the app built from this tutorial at the end of the post. Here we go!
Table of Contents
Key Points
- Query analysis is an important concept to understand in SEO, and Google‘s use of machine learning has rapidly increased since 2013.
- Intent and entity recognition are key to understanding queries and helping pages rank higher in search results.
- Intent is determined by how Google‘s understanding of the query intent matches the intent of the page you want to rank for that query.
- Entities are words and concepts that Google explicitly understands in queries that lead to a website.
- Python modules and manual intent lists are used to filter queries into intent dataframes and calculate intent stats.
- A master word list is created and cleaned, and the Google Knowledge Graph API is used for entity recognition and frequency.
- An app is available to use the query analysis, and the script can be extended and optimized.
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab
- Query export from GSC or a CSV with queries under a column named “Top queries” (English only)
- Google Knowledge Graph API Key
Import Modules
- pandas: for importing the CSV file and displaying the data
- nltk: for tokenizing and tagging the word types (‘punkt‘ download is for tokenizing and ‘averaged_perceptron_tagger‘ for word type tagging)
- requests: for sending the API calls
- json: for processing the API response
- collections: for the word count function
Let’s first import the modules needed for this script expressed above.
import pandas as pd
import requests
import json
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from collections import Counter
%load_ext google.colab.data_table #only if you're in Google Colab
Import Queries and Setup Intent Lists
First, we store your Google Knowledge Graph API key in a variable. Now we import the queries CSV from GSC into a dataframe using pandas read_csv(). We’ll want to do a percentage calculation later on so let’s get the total number of queries in the new dataframe. Lastly, we convert the queries dataframe series into a list for easier manipulation for our processing.
apikey= "" # ENTER YOUR GOOGLE KNOWLEDGE GRAPH API KEY HERE
df = pd.read_csv("queries.csv")
total_queries = len(df.index)
query_list = df['Top queries'].tolist()
Now is when you were expecting some next-level NLP machine learning right? Nope! There is no doubt the evolution of this script in efficiency and accuracy lies in a machine learning process, but I’m not there yet in my own development and sometimes a practical method still works pretty well. In this case, we’re just going to manually identify intent words. Feel free to add additional words you see as relevant to your industry.
Informative: People looking for information, top-funnel type content!
Transactional: People looking for something to buy
Commercial: People looking for comparisons or lists
Custom: This could have been named ‘Navigational’ as it can be best used for variations of your brand, but feel free to use it however you wish to segment and label a category of queries.
informative = ['what','who','when','where','which','why','how'] transactional = ['buy','order','purchase','cheap','price','discount','shop','sale','offer'] commercial = ['best','top','review','comparison','compare','vs','versus','guide','ultimate'] custom = ['brand variation 1','brand variation 2','brand variation 3']
Filter Queries into Intent Lists
Next, we build new dataframes for each intent category. This simply searches the master dataframe for the words in each list and if found it adds it to the corresponding list. Note, this is where we see the first crack in our method. It’s possible to trigger a hit if the word in the list is anywhere in the queries, even if it’s part of another word. Second, this can end up adding a query to multiple dataframes if multiple intents are detected. We handle that in a bit, but not in a great way. Lastly, as is this will return intent words that are part of another word. This can be mitigated by putting a space after the intent word in the above lists or using some regex. I will be updating this script later this week with this improvement after some testing.
info_filter = df[df['Top queries'].str.contains('|'.join(informative))]
trans_filter = df[df['Top queries'].str.contains('|'.join(transactional))]
comm_filter = df[df['Top queries'].str.contains('|'.join(commercial))]
custom_filter = df[df['Top queries'].str.contains('|'.join(custom))]
Now we simply add a new column to each dataframe so we have the intent associated with the query.
info_filter['Intent'] = "Informational" trans_filter['Intent'] = "Transactional" comm_filter['Intent'] = "Commercial" custom_filter['Intent'] = "Custom"
In order to get some stats on how many of each intent was found, we’ll run len() on each dataframe.
info_count = len(info_filter) trans_count = len(trans_filter) comm_count = len(comm_filter) custom_count = len(custom_filter)
Display Intent Stats
Now we can output the total number of queries, how many of each intent, and then calculate the percentage of the total queries for each intent, rounding to one decimal place.
print("Total: " + str(total_queries))
print("Info: " + str(info_count) + " | " + str(round((info_count/total_queries)*100,1)) + "%")
print("Trans: " + str(trans_count) + " | " + str(round((trans_count/total_queries)*100,1)) + "%")
print("Comm: " + str(comm_count) + " | " + str(round((comm_count/total_queries)*100,1)) + "%")
print("Custom: " + str(custom_count) + " | " + str(round((custom_count/total_queries)*100,1)) + "%")
Merge Intent Dataframes
Once we output the stats we want to build the master dataframe. We simply use the pandas concat() to add them all together. Then we sort by clicks descending. To get rid of those duplicate intents we use the pandas drop_duplicates() function of the ”Top queries’ column, only keeping the first. Obviously, this is a bit problematic, and would love advice on how to handle it more intelligently. One thought is to return all the intents, but that also is not perfect. I also wanted to rearrange the columns so intent wasn’t at the end. Lastly here we can output the final intent dataframe.
df_intents = pd.concat([info_filter,trans_filter,comm_filter,custom_filter]).sort_values('Clicks', ascending=False)
df_intents = df_intents.drop_duplicates(subset='Top queries', keep="first")
df_intents = df_intents[ ['Top queries'] + ['Clicks'] + ['Impressions'] + ['Intent'] + ['CTR'] + ['Position'] ]
df_intents
Start Entity Recognition
Now we move on to the entity recognition and keyword counter. For this, our method is to tokenize the query phrases, clean the word list, send to Google Knowledge Graph API and then run a function counting the words.
First here we’ll create our empty list to house all the queries. Then we loop through the query_list we made earlier from the CSV, split the queries by space, and add them to the master list. This essentially tokenizes all the queries into a single list.
ma_query_list = []
for x in query_list:
ma_query_list.extend(x.split(" "))
Clean Query Word List
Now we do some clean-up on the list because at the moment it will contain a lot of stop words. First, we send the list to the function nltk.pos_tag() which analyzes the words and attaches a word type label to the word creating a new list that contains two item lists in a list like [[‘bird’,’NN’],[‘Shave’,’VB’]]. Next, we do some list comprehension to create a new list that only contains nouns and verbs. You can absolutely choose other word types and the options are here. Next, we create another list with only the word, not the type. It’s no longer needed after filtering them. Lastly, we grab the total number for stats later.
query_tokens = nltk.pos_tag(ma_query_list) query_tokens = [x for x in query_tokens if x[1] in ['NN','NNS','NNP','NNPS','VB','VBD']] query_tokens = [x[0] for x in query_tokens] total_tokens = len(query_tokens)
We now have our cleaned list of words from all of our queries. The next step is to leverage the Counter() and most_common() functions from the collections module we imported. This will do the word counting and return the top X. I choose 50, but you can adjust this. At this time we also create our master dataframe for the next process.
counts = Counter(query_tokens).most_common(0) df2 = pd.DataFrame(columns = ['Keyword', 'Count', 'Percent','Entity Labels'])
Build Google Knowledge Graph API Function
Next, we create the function to check the Google Knowledge graph if the word we send has an entry. If it does, it means it’s an entity and we’ll capture what Google labels it (it can multiple types). Because this is a large chuck I’ll just provide what is happening in a list.
- We define the function and send in a single word from the master word list and the API Key.
- We build the API URL using the keyword and API key. We also limit the results to only the first entry hit. We assume this is the most relevant.
- We build the API request call and then store the response in a JSON object.
- We parse the JSON response to capture only the entity type. If the word is not in the graph it will error and we’ll set the entity to “none”.
- There can be multiple entity types put in a list form so we’ll loop through them and reconstruct them into a string list.
def kg(keyword, apikey):
url = f'https://kgsearch.googleapis.com/v1/entities:search?query={keyword}&key={apikey}&limit=1&indent=True'
payload = {}
headers= {}
response = requests.request("GET", url, headers=headers, data = payload)
data = json.loads(response.text)
try:
getlabel = data['itemListElement'][0]['result']['@type']
except:
getlabel = ['none']
labels = ""
for item in getlabel:
labels += item + ","
return labels
Process Word List Through GKG Function Above
It’s now time to loop the words in our counts list which contains all the query words and frequency counts. We’ll want some stats on our entity type labels so we’ll make an empty list to house them. Then we loop through the counts list. We want to calculate the percent for understanding it compared to the whole list. Then we send the word and the API key to the function we created above to call the Google Knowledge Graph API and store that entity type list. For the entity stats, we store those types by resplitting them into a list. We use rstrip() to remove the trailing comma when we formed the entity type list string. I’m sure there is a better way to this, but it worked for me. We then find the total number of entity types, create a dictionary object to house the entity information and then append it to the master dataframe with the other entities.
master_labels = []
for key, value in counts:
percent = round((value/total_tokens)*100,1)
kg_label = kg(key, apikey)
master_labels.extend(kg_label.rstrip(kg_label[-1]).split(","))
total_entities = len(master_labels)
data = {'Keyword': key, 'Count': value, 'Percent': percent, 'Entity Labels': kg_label}
df2 = df2.append(data, ignore_index=True)
Build Entity Stats
The last we do is run the entity list through the same Counter() and most_common() functions from the collections module we used earlier. Then we simply loop through the new list and calculate the percentage and print the result. Then we display the dataframe. Easy!
entity_counts = Counter(master_labels).most_common(5) for key, value in entity_counts: print(key + ": " + str(value) + " | " + str(round((value/total_entities)*100,1)) + "%") df2
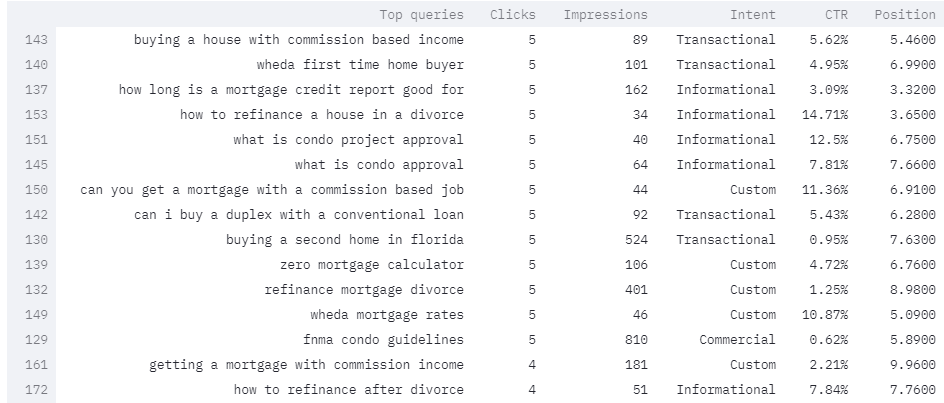
Query Intent Output Example
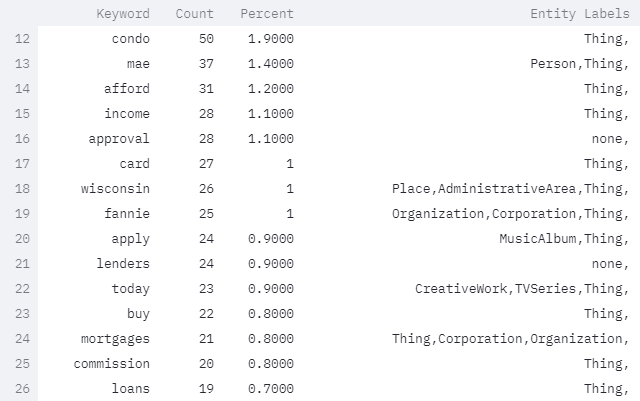
Entity and Entity Count Output Example
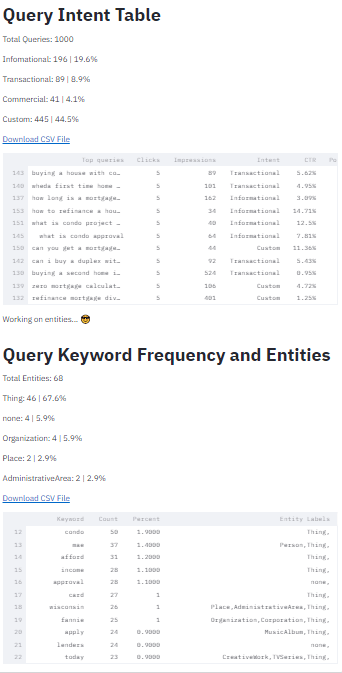
Full Query Analysis App Output
Conclusion
So there you have it! You can now can within seconds fairly accurately label intent, along with entity recognition and entity frequency for your GSC queries or otherwise. I challenge you to take this script and extend it. Continue to build features in this script and increase its accuracy. One thing I’d like to tackle is to support languages other than English. This would likely take some NLP and machine learning. I’d love to hear your ideas for this.
Now get out there and try it out! Follow me on Twitter and let me know your applications and ideas!
SEO Intent FAQ

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024