Compare Web Page Entities with Google NLP in Python
This is part 2 of a two-part series. Please see Getting Started with Google NLP API Using Python first.
For search engines and SEO, Natural Language Processing (NLP) has been a revolution. NLP is the methodology by which machines understand human language. This matters because machines perform the bulk of page evaluation. While some knowledge of the science behind NLP is useful, we now have tools that let us use NLP without a data science degree. By understanding how machines interpret our content, we can adjust for misalignment or ambiguity. Let’s go!
In this intermediate tutorial (part 2), using two web pages, I’ll show you how you can:
- Compare entities and their salience between two web pages
- Display missing entities between two pages
I recommend reading the full Google NLP documentation for instructions on setting up Google Cloud Platform, enabling the NLP API, and configuring authentication.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and you have a basic understanding of Python syntax
- Access to a Linux installation (Ubuntu recommended) or Google Colab
- Google Cloud Platform account
- NLP API Enabled
- Credentials created (service account) and JSON file downloaded
Import Modules and Set Authentication
Several modules must be installed and imported. If you use Google Colab, many are preinstalled; otherwise install the Google NLP client library.
- os – setting the environment variable for credentials
- google.cloud – Google’s NLP modules
- pandas – for organizing data into dataframes
- fake_useragent – for generating a user agent when making a request
- matplotlib – for the scatter plots
Of those, two need installation: fake_useragent and a specific pandas version (Google Colab may include an older pandas). Install the packages shown below.
!pip3 install fake_useragent
!pip3 install pandas==1.1.2
import os from google.cloud import language_v1 from google.cloud.language_v1 import enums from google.cloud import language from google.cloud.language import types import matplotlib.pyplot as plt from matplotlib.pyplot import figure from fake_useragent import UserAgent import requests import pandas as pd import numpy as np
Next, set the environment variable that points to the credentials JSON file for the Google API. Google requires the credentials be available via an environment variable. The example below assumes Google Colab (remember to upload the file). To set the variable on Linux (Ubuntu), add the line in ~/.profile or ~/.bashrc and replace the path as needed. Keep this JSON file secure.
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = "path_to_json_credentials_file"
Build NLP Function
Because the same process evaluates both pages, create a function to reduce redundant code. The function processhtml() below will:
- Create a new user agent for the request header
- Make the request to the web page and store the HTML content
- Initialize the Google NLP
- Communicate to Google that you are sending them HTML, rather than plain text
- Send the request to Google NLP
- Store the JSON response
- Convert the JSON into a python dictionary with the entities and salience scores (adjust rounding as needed)
- Convert the keys to lower case (for comparing)
- Return the new dictionary to the main script
def processhtml(url):
ua = UserAgent()
headers = { 'User-Agent': ua.chrome }
res = requests.get(url,headers=headers)
html_page = res.text
url_dict = {}
client = language_v1.LanguageServiceClient()
type_ = enums.Document.Type.HTML
language = "en"
document = {"content": html_page, "type": type_, "language": language}
encoding_type = enums.EncodingType.UTF8
response = client.analyze_entities(document, encoding_type=encoding_type)
for entity in response.entities:
url_dict[entity.name] = round(entity.salience,4)
url_dict = {k.lower(): v for k, v in url_dict.items()}
return url_dict
Process NLP Data and Calculate Salience Difference
Now that we have the function, set the variables containing the web page URLs to compare and send them to the function.
url1 = "https://www.rocketclicks.com/seo/" url2 = "http://www.jenkeller.com/websitesearchengineoptimization.html" url1_dict = processhtml(url1) url2_dict = processhtml(url2)
We now have NLP data for each URL. Next, compare the two entity lists. When entities match, calculate the difference in salience if the competitor’s score is higher. This code snippet will:
- Create an empty dataframe with four columns (Entity, URL1, URL2, Difference). URL1 and URL2 contain the salience scores for each entity on that URL.
- Compare each entity in both lists; if they match, store each salience score in variables.
- If the competitor’s salience score for a keyword is greater than yours, record the difference (adjust rounding as needed).
- Add the comparison data for the entity to the dataframe.
- Print the dataframe after processing all matched entities.
df = pd.DataFrame([], columns=['Entity','URL1','URL2','Difference'])
for key in set(url1_dict) & set(url2_dict):
url1_keywordnum = str(url1_dict.get(key,"n/a"))
url2_keywordnum = str(url2_dict.get(key,"n/a"))
if url2_keywordnum > url1_keywordnum:
diff = str(round(float(url2_keywordnum) - float(url1_keywordnum),3))
else:
diff = "0"
new_row = {'Keyword':key,'URL1':url1_keywordnum,'URL2':url2_keywordnum,'Difference':diff}
df = df.append(new_row, ignore_index=True)
print(df.sort_values(by='Difference', ascending=False))
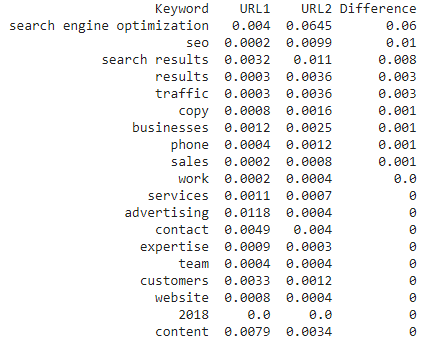
Example Output
This output shows entities found on both pages where Google NLP assigns higher salience on the competitor page. These are keywords worth investigating to determine whether your page can communicate those concepts more clearly. Salience scores are rounded to three decimal places; adjust the rounding to reveal finer differences.
Find Difference in Named Entities
Next, it’s useful—especially for a competitor page that is outranking yours—to find entities present on their page but missing from yours. The snippet below:
- Uses set() to compare entities between the two dictionaries; entities present in the competitor list but not yours are stored in diff_lists.
- Because set() operates on keys, it discards values (the salience scores), so we add them back in.
- Create the final_diff dictionary and convert it to a dataframe.
- Print the dataframe and sort by score in descending order.
diff_lists = set(url2_dict) - set(url1_dict)
final_diff = {}
for k in diff_lists:
for key,value in url2_dict.items():
if k == key:
final_diff.update({key:value})
df = pd.DataFrame(final_diff.items(), columns=['Keyword','Score'])
print(df.head(25).sort_values(by='Score', ascending=False))
Example Output
This list shows the top 25 entities by salience that appear on the competitor page but not on your page. Adjust head() to view more or fewer entries. Use this to find entity opportunities that competing pages use but yours does not.

Conclusion
I hope you found this two-part series useful for getting started with NLP and comparing entities between web pages. These scripts are foundations and can be extended as needed. Explore data blending with other sources to mine further insights. Enjoy, and as always, follow me on Twitter and let me know what you think and how you’re using Google NLP!
Google NLP and Entities FAQ

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024
Related Python Tutorials
- Calculate SERP Rank Readability Scores Using Python

- Compare Wikipedia Search Data with Google Trends with Python

- Getting Started with Google NLP API Using Python

- Build an N-Gram Text Analyzer for SEO using Python

- Evaluate Sentiment Analysis in Bulk with spaCy and Python






- Use Machine Learning and Python for Easy Text Classification

- Use Python to Label Query Intent, Entities and Keyword Count

- Overlay GSC Data with Google Algo Updates Using Python

- Webpage Word Sense Disambiguation for SEO Using Python and NLTK
- Create a Topical Internal Link Graph for SEO with NetworkX and Python