Detect Google SERP Title and Snippet Rewrites with Python
Back in early August of 2021 word began to travel through the industry that titles were being rewritten in the Google SERPs in a frequency and manner not seen before. Plenty of SERP analysis has been done to understand the why, how, and what to do about it, but it starts with an analysis of the impact on your own websites. You want to know, how many titles are being rewritten and how. This is dead simple if you have a handful of pages. Just plug the URLs into the search bar and manually record. If you have more than just a handful it becomes either annoying or straight impossible.
Since the rewriting event, several tools have been released by SEO platforms and other SEOs to check for title rewrites, but I wanted to try it for myself. For this tutorial, I’ll be showing you step-by-step how to compare your page titles and meta descriptions to what is shown in the SERPs. Then for a bonus, detect if the SERP title is using the page’s H1.
There is a big catch here, unfortunately. SERP analysis at scale is generally only possible using a SERP scraping API service and they are not cheap. For this tutorial, I am using SERP API’s free plan (any SERP API service should work with a little script adjustment) which allows for 100 scrapes a month. That is not much and will only allow you to scrape your site once a month for even small blogs. Even if you have resources for a higher plan, you’ll need to be careful which URLs you want to send in for analysis and how often.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab.
- SERP API key or similar scrape service (you’ll need to make script adjustments if not SERP API)
- ScreamingFrog HTML crawl list or CSV with URLs (if not from ScreamingFrog either mirror the column names or make adjustments to the code below)
Install Modules
There are two modules we’re going to use that aren’t core Python (you should have pandas installed already). Remember if you are running in Google Colab to add an exclamation mark at the beginning.
pip3 install google-search-results
pip3 install polyfuzz
Import Modules
- pandas: For importing the URL list and then storing the comparison results
- GoogleSearch: The SERP API module
- PolyFuzz: Calculating the comparison similarity scores
import pandas as pd from serpapi import GoogleSearch from polyfuzz import PolyFuzz
Let’s start by importing the crawl CSV file into a pandas dataframe. We don’t need most of the ScreamingFrog crawl columns so let’s only import the columns we care about. You’ll notice a comment hashmark at the end of the read_csv function. If you want to test the script using a small subset of URLs, remove the hashmark and change the number to the number of URLs you want to process. This can save you from blowing your entire API credits in one go.
The following 4 lines are as follows:
- Filter out rows that aren’t marked as “Indexable”.
- Replace NaN (no value) values with a string. This is needed for comparison processing.
- After filtering for indexability, we no longer need the column, so we can drop it.
- Many meta descriptions are more characters than what is displayed in the SERPs. To get a better idea of total rewrites we’ll cap the number of characters to 150 in our crawl list data. Otherwise, you’ll find most descriptions will be flagged because they go to ellipses.
df = pd.read_csv("internal_html.csv")[["Address","Indexability","Title 1","Meta Description 1","H1-1"]]#[:5]
df = df[df["Indexability"] == "Indexable"]
df = df.fillna('None')
df.drop(['Indexability'], axis=1, inplace=True)
df["Meta Description 1"] = df["Meta Description 1"].apply(lambda x: x[:150])
Next, we create 4 empty lists that will store the SERP title, SERP snippet, and then both comparison scores.
serp_title_list = [] serp_desc_list = [] serp_title_list_diff = [] serp_desc_list_diff = []
This next part cycles through the dataframe that contains the crawl URL list and sends each URL to the SERP API. The SERP API will make a query with that URL and return the title and meta description snippet. Make sure you enter your SERP API key in api_key. We’ll store both of those in variables that get appended to each corresponding list. Notice we cap the meta snippet to 150 characters as we did for the crawl list earlier. This will gives us a more accurate comparison. If you have many long page titles, you may decide to do the same for page titles.
for index, row in df.iterrows():
params = {
"q": row["Address"],
"hl": "en",
"gl": "us",
"api_key": ""
}
search = GoogleSearch(params)
results = search.get_dict()
serp_title = results["organic_results"][0]["title"]
serp_desc = results["organic_results"][0]["snippet"][:150]
serp_title_list.append(serp_title)
serp_desc_list.append(serp_desc)
Now that we have our titles and meta snippets for each URL we can add the lists to our dataframe as new columns.
df["SERP Title"] = serp_title_list df["SERP Meta"] = serp_desc_list
It’s now time to calculate a similarity score using PolyFuzz module which is a great fuzzy string matcher. Essentially this calculates a score based on how many steps it would take to turn one string into the other. A pair of strings that are closer will take fewer steps. The scores range from 0-1 with 1 being a perfect match. Simple! We run this on each title pair, meta snippet pair, and then the H1 to the SERP title. Each result landing in its own dataframe.
model = PolyFuzz("EditDistance")
model.match(serp_title_list, df["Title 1"].tolist())
df2 = model.get_matches()
model.match(serp_desc_list, df["Meta Description 1"].tolist())
df3 = model.get_matches()
model.match(serp_title_list, df["H1-1"].tolist())
df4 = model.get_matches()
Next, we take those similarity scores in each dataframe, convert them to a list, so we can then create new columns in our master frame with that score data.
df["SERP Title Diff"] = df2["Similarity"].tolist() df["SERP Meta Diff"] = df3["Similarity"].tolist() df["SERP H1/Title Diff"] = df4["Similarity"].tolist()
All that is left is a little formatting as follows
- Sort by SERP title diff descending. The larger the changes the higher up the URL. You could also switch this with the meta snippet.
- Round the similarity scores for each to 3 places
df = df.sort_values(by='SERP Title Diff', ascending=True) df["SERP Title Diff"] = df["SERP Title Diff"].round(3) df["SERP Meta Diff"] = df["SERP Meta Diff"].round(3) df["SERP H1/Title Diff"] = df["SERP H1/Title Diff"].round(3)
The final step is either to output the dataframe to the screen or to save it as a CSV file. Uncomment which you want.
#df
#df.to_csv("title-snippet-rewrites.csv")
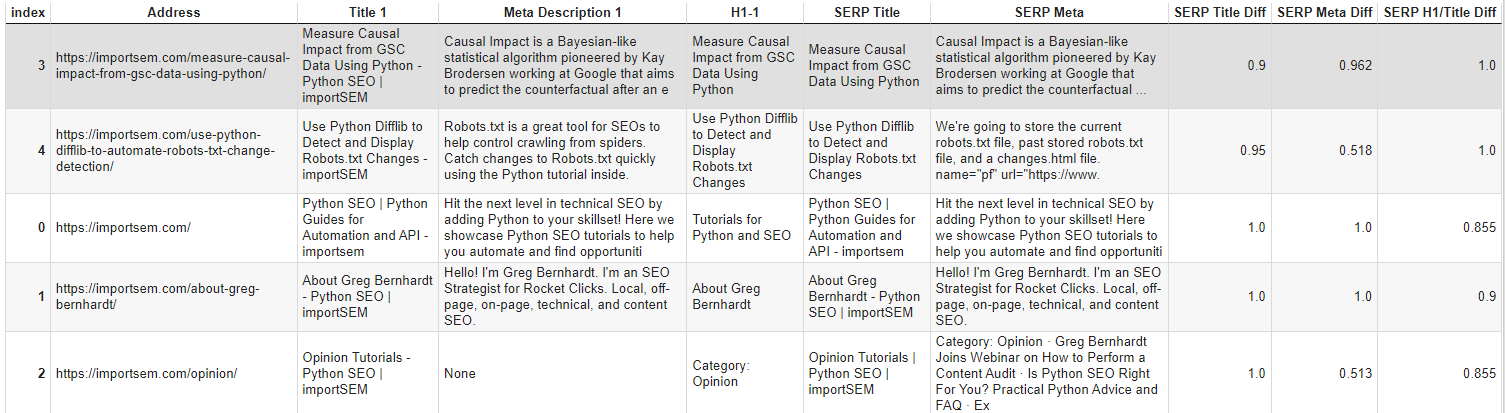
Output
I only ran this with the first 5 URLs in my crawl. Even with this tiny dataset, it’s telling us the following:
- Google is rewriting 2/5 of the page titles.
- Google is using the H1 for both of the title rewrites.
- Google is rewriting 4/5 of the meta description snippets
Conclusion
Google’s latest adjustments to their title rewriting system sure shocked the industry. It’s time to get an understanding of the impact on your site. Now you have the framework to begin that analysis! Remember to try and make my code even more efficient and extend it into ways I never thought of! One idea would be to use keywords to find your URL instead of searching for the URL. I suspect over time we’re going to see title rewriting based on query and personalization (maybe they already are!).
Now get out there and try it out! Follow me on Twitter and let me know your applications and ideas!
Google SERP Title FAQ

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024