
Automate Google Lighthouse with Python for SEO Reports
Google’s web page scanner Lighthouse has been a fixture among the most important tools for evaluating web pages. At a high level, this scanner measures a page’s performance, SEO, accessibility, and best practices. At a deeper level, it provides granular metrics for each category and displays recommendations. Most SEOs are familiar with running Lighthouse within Google Chrome’s DevTools. Running Lighthouse in the browser is easy and convenient, but it is manual and difficult to scale. What if you want to run Lighthouse on multiple pages daily? Python, as usual, comes to the rescue. This tutorial provides the bare bones needed to set up automated Lighthouse scanning. You can easily extend it for your own purposes.
Table of Contents
Key Points
- Google‘s web page scanner Lighthouse measures page performance, SEO, accessibility, and best practices
- Python can be used to automate the use of Lighthouse
- Requirements and Assumptions include Python 3, access to Linux or Google Colab, and Lighthouse 6.4.1
- Install the Lighthouse CLI and import the required modules
- Create an empty dataframe and support variables
- Loop through the list of URLs and run Lighthouse
- Process the JSON report, open the file, and grab the high–level ratings
- Add ratings to the dataframe, export to CSV, and automate the scan with crontab
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab. I don’t recommend Google Colab for this, as performance is not great.
- This script has been tested on Lighthouse 6.4.1, which was current as of this tutorial’s publishing date.
Starting the Script
First, install the lighthouse CLI from npm, using the node package manager. It is easy to install; be sure to read the documentation and consider the available options. An alternative to running Lighthouse locally is to use the PageSpeed Insights API. If you are running from Google Colab, put an exclamation point at the beginning; otherwise, enter the following in your terminal:
npm install -g lighthouse
Next, we import our required modules.
- json: to process the JSON output from Lighthouse
- os: to execute the local Lighthouse CLI
- pandas: for storing the results and exporting to CSV
- datetime: used in naming the JSON file
import json import os import pandas as pd from datetime import datetime
Create Dataframe
We’re going to store each URL’s high-level ratings in a dataframe. Let’s set up that empty dataframe to use later. Note: there are dozens of metrics you can pull from these reports. Open the JSON output after running Lighthouse to see the available metrics, then add columns to the dataframe and adjust the JSON extraction accordingly.
df = pd.DataFrame([], columns=['URL','SEO','Accessibility','Performance','Best Practices'])
Create support variables
Now we set up a few simple variables we’ll use throughout. We’ll use the name and getdate variables to name the output file, and the URL list is what we’ll loop through and scan. You have two options for populating the list of URLs to scan: put them directly in a list in the code, or import them from a CSV (for example, a Screaming Frog crawl file).
name = "RocketClicks"
getdate = datetime.now().strftime("%m-%d-%y")
urls = ["https://www.rocketclicks.com","https://www.rocketclicks.com/seo/","https://www.rocketclicks.com/ppc/"]
Use the code below if you are importing from a crawl file. Change YOUR_CRAWL_CSV to the path/name of your crawl CSV file. Then convert the dataframe to a Python list.
df_urls = pd.read_csv("YOUR_CRAWL_CSV.csv")[["Address"]]
urls = df_urls.values.tolist()
Run Lighthouse
Now it’s time to loop through the list of URLs and run Lighthouse. We’ll use the os Python module to execute Lighthouse via the CLI. Be sure to check the docs for details on available options. Also, change the output path to match your local environment.
for url in urls:
stream = os.popen('lighthouse --quiet --no-update-notifier --no-enable-error-reporting --output=json --output-path=YOUR_LOCAL_PATH'+name+'_'+getdate+'.report.json --chrome-flags="--headless" ' + url)
Because the script launches an external application, we need to pause and wait for Lighthouse to finish. I have found 2 minutes (120 seconds) works for most pages; tweak this as needed if you get an error that the JSON output file doesn’t exist. Alternatively, write a loop that waits until the output file exists before continuing. Once the pause is over and Lighthouse has likely finished, build the full path to the file so we can process it in the next snippet. Be sure to change “YOUR_LOCAL_PATH”.
time.sleep(120)
print("Report complete for: " + url)
json_filename = 'YOUR_LOCAL_PATH' + name + '_' + getdate + '.report.json'
Process Report
Now let’s open that JSON report file and start processing it.
with open(json_filename) as json_data:
loaded_json = json.load(json_data)
As mentioned earlier, there is a lot of data in this report file; go through it and pick the fields you want to store. For this tutorial, we’re grabbing the high-level ratings for the four main categories. These scores are out of 100. Lighthouse records them as floats from 0.00 to 1.00, so we multiply by 100 (1.00 equals 100%).
seo = str(round(loaded_json["categories"]["seo"]["score"] * 100))
accessibility = str(round(loaded_json["categories"]["accessibility"]["score"] * 100))
performance = str(round(loaded_json["categories"]["performance"]["score"] * 100))
best_practices = str(round(loaded_json["categories"]["best-practices"]["score"] * 100))
Add Data to Dataframe
Now we take those high-level ratings, put them in a dictionary, and append them to the dataframe. Each URL will be added to this dataframe. After this, the loop continues to the next URL (if any).
dict = {"URL":url,"SEO":seo,"Accessibility":accessibility,"Performance":performance,"Best Practices":best_practices}
df = df.append(dict, ignore_index=True).sort_values(by='SEO', ascending=False)
Finally, we have all ratings in the dataframe. From here you can perform further manipulation, pipe results into another script, or store them in a database. In this tutorial, we’ll simply export the data to a CSV file for use in Google Sheets or Excel. Be sure to replace “SAVE_PATH”.
df.to_csv(SAVE_PATH/'lighthouse_' + name + '_' + getdate + '.csv') print(df)
Output
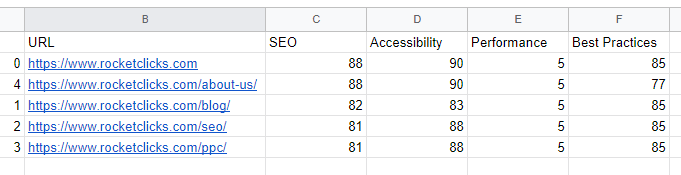
Automating the Scan
If your Lighthouse script runs correctly when executed manually, it’s time to automate it. Linux provides a built-in scheduler via crontab. The crontab stores scheduled entries and lets you dictate when to execute them (time of day, day of week, day of month, etc.).
But first, add a shebang to the very top of your script; it tells Linux to run the script using Python 3:
#!/usr/bin/python3
To edit the crontab, run this command:
crontab -e
It will likely open the crontab file in the vi editor. On a blank line at the bottom of the file, type the following line. This will run the script at midnight every Sunday. To change the schedule, use the cronjob time editor. Customize the path to your script.
0 0 * * SUN /usr/bin/python3 PATH_TO_SCRIPT/filename.py
If you want a log file to record each run, use this variant (customize paths):
0 0 * * SUN /usr/bin/python3 PATH_TO_SCRIPT/filename.py > PATH_TO_FILE/FILENAME.log 2>&1
Save the crontab file and you’re set. Note: your computer must be on when the cronjob is scheduled to run.
Conclusion
Lighthouse has become a standard tool for SEOs to understand their pages’ well-being. It’s time to level up your use of Lighthouse and move beyond DevTools. Automation and targeted customization using Python are great ways to achieve that. Extend this script by inserting data into a database or use the Google Sheets API to add results to a sheet. Please follow me on Twitter for feedback and to see interesting extensions of the script. Enjoy!
Looking for something more comprehensive? See Hamlet Batista’s BrightonSEO slides on Automating Lighthouse for large-scale approaches.
Google Lighthouse and Python FAQ

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024

















