Retrieve the Google Cache Date for URLs Using Python
Viewing cached links in Google is a common troubleshooting and information-recovery method used by SEOs. Google caches some pages it crawls and creates a snapshot of the page at the time of the crawl. You will often notice missing resources or images, so the cache is rarely a perfect copy, but it is useful for seeing what content Google has stored and diagnosing omissions. There is also a correlation between how often Google caches a page and its perceived importance: high-value pages are often cached daily, while lower-value pages can go weeks or months without a new cache date. Below I’ll show you how to scrape the cache date for a set of URLs so you can run this analysis yourself.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and you understand basic Python syntax
- Access to a Linux installation (Ubuntu recommended) or Google Colab
Starting the Script
First, install the fake_useragent module to use in our request headers. This can help avoid light abuse detection—Google is understandably sensitive to non-human requests. If you become blocked you can try the proxy-requests module, but I had limited success: many proxies were already blocked and the module ran very slowly. The most reliable tactic I’ve found is adding delays between calls. If you are using Google Colab, prefix pip3 with an exclamation mark (for example, !pip3).
pip3 install fake_useragent
Next, we import the modules we will use.
- requests to fetch the Google cache page
- re for regular expressions to extract the date from the cache page
- fake_useragent to generate random User-Agent strings
- numpy to select a random delay value from a list
- time for pausing execution (sleep)
- pandas to read a CSV of URLs and to store the scrape results
import requests import re from fake_useragent import UserAgent import numpy as np import time import pandas as pd
Build the URL List
Let’s build the URL list of pages whose cache dates we want to check.
urls = ['https://www.rocketclicks.com/seo/','https://www.rocketclicks.com/ppc/','https://www.rocketclicks.com/about-us/']
If you have a CSV of URLs you can use the code below instead. Modify the file path and the column name where the URLs are stored. We load the CSV into a pandas DataFrame and then convert the URL column to a list.
loadurls = pd.read_csv("PATH_TO_FILE")
urls = loadurls['COLUMN_NAME_WITH_URLS'].tolist()
Build Loop Counter and Pandas Dataframe
We will add a script delay between calls but avoid an extra pause after the last request. To do this, create a counter variable and compute the total number of URLs in the list.
Then create a pandas DataFrame to store the scrape results. It contains two columns: URL and Cache Date.
counter = 0
urlnum = len(urls)
d = {'URL': [], 'Cache Date': []}
df = pd.DataFrame(data=d)
Begin Processing URLs
Start the loop to process the URL list. We’ll use the cache: search operator and strip any scheme and the www. prefix so the query uses the root domain.
for url in urls:
urlform = url.replace('https://','')
urlform = urlform.replace('http://','')
urlform = urlform.replace('www.','')
Build the Cache Query
Build the query using the cache: operator and the cleaned URL. Also create a delay list containing integers from 10 to 20 (seconds). Randomizing delays with numpy helps avoid triggering Google’s blocking. Finally, build the full query URL we will request. I have been learning about “f-strings“, so I use them here to insert variables into strings.
query = "cache:"+urlform
delays = [*range(10, 21, 1)]
queryurl = f"https://google.com/search?q={query}"
Request Google Cached Page
Next, build a fake User-Agent, assign it to the headers, and make the request to Google.
ua = UserAgent()
header = {"user-agent": ua.chrome}
resp = requests.get(queryurl, headers=header,verify=True)
print(urlform)
Process Cached Pages
The request has been made; check the response status. If Google returns status code 200 the request succeeded; otherwise you may be blocked (often temporarily). If successful, use RegEx to extract the cache date text from the page. Below is a breakdown of the RegEx.
The cache date is in this format: Sep 12, 2020
[a-zA-z]{3}\s[0-9]{1,2},\s[0-9]{4}
[a-zA-z]{3} matches three letters (the month abbreviation)
\s[0-9]{1,2} matches a space followed by 1–2 digits (the day)
,\s matches a comma and a space
[0-9]{4} matches four digits (the year)
After matching the cache date, create a dictionary with the URL and cache date, then append it to the DataFrame created earlier. Each URL will be added to the DataFrame this way.
if resp.status_code == 200:
getcache = re.search("[a-zA-z]{3}\s[0-9]{1,2},\s[0-9]{4}",resp.text)
g_cache = getcache.group(0)
newdate = {"URL":urlform,"Cache Date":g_cache}
df = df.append(newdate, ignore_index=True)
else:
print("Google may have blocked you, try again in an hour")
Set Script Delay and Print Dataframe
Finally, update the counter and, if there are more URLs to process, select a random delay from the list using numpy and pause the script with time.sleep(). This random pause helps avoid detection by preventing consistent request intervals—humans rarely make many searches at precisely the same intervals. At the end, display the DataFrame containing the collected cache dates.
counter += 1
if counter != urlnum:
delay = np.random.choice(delays)
#print("sleeping for "+str(delay)+" seconds" + "\n")
time.sleep(delay)
df
Example Output
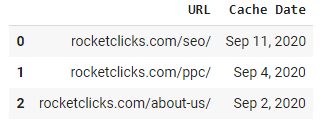
Conclusion
This demonstrates how to grab cache dates for your URLs. The main challenge is avoiding temporary blocks from Google. From here you can store the results in a database, use them in reporting, or feed them to another script. Enjoy! Don’t forget to follow me and let me know how you are using or extending this script.
Google Cache Date FAQ
How can SEOs retrieve the Google Cache date for URLs using Python?
Use Python to automate queries of Google’s cache and extract cache dates for specific URLs.
Is authentication required for accessing Google’s cache date with Python?
No; scraping publicly available cache pages typically does not require authentication.
What Python libraries are commonly used for extracting data from web pages, including cache dates?
Beautiful Soup and requests are common Python libraries for web scraping and extracting information such as Google Cache dates.
Can Python scripts be used to retrieve cache dates for multiple URLs in a batch process?
Yes—scripts can iterate through a list of URLs to retrieve Google Cache dates in batch.
Where can I find examples and documentation for using Python to retrieve Google Cache dates for URLs?
See online tutorials and documentation on web scraping with Python for examples and guidance on extracting data, including cache dates from Google’s cache pages.

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024