
Analyze Words Using WordsAPI App and Python for SEO
Ask any SEO writer, the words you choose for your copy matter. Sometimes we think we know the attributes, relationships, and the word universe words live in, but often we don’t. It can be a challenge to generate ideas and inspiration from singular words. Understanding words can help you explore possibilities for your content that result in much richer and fuller communication for your content. To help with that I’ve developed an app that connects with the WordsAPI. All you need to do is supply a word and the app does the rest.
Note this isn’t one of my traditional tutorials because there isn’t too much to this app. It’s repetitive after the first API call and I have an app you can use, so I won’t be explaining much. This post is mostly for those who want to customize what I have started, so I have just chunked out the code here.
Streamlit is quite easy to learn the basics of, although it has plenty of limitations. I’m happy to say that the development is very fast-paced and new features are coming out every month. I will not be going over the basics of setting up Streamlit. You can find that setup information here. Please take a few minutes to familiarize yourself with the basics here.
Before we begin, remember to watch the indents of anything you copy here as sometimes the code snippets don’t copy perfectly.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu)
- rapidapi.com free account (2,600 free API calls a month)
- Streamlit installed locally and optionally sign up for an app deployment account
Import Modules
- requests: for making the API calls
- json: for processing the API responses
- streamlit: a framework for making the script into an app
- streamlit.components.v1: enables the use of a scrollable HTML container
Let’s first import the modules needed for this script expressed above.
import requests import json import streamlit as st import streamlit.components.v1 as comp
Next, we handle our app styling, title, and directions. Note I make use of the Streamlit function st.markdown()
st.markdown("""
<style>
.big-font {
font-size:50px !important;
}
h3 {
padding-top:0px;
margin-top:-5px;
}
</style>
""", unsafe_allow_html=True)
st.markdown("""
<p class="big-font">WordAPI Wizard 1.0</p>
<b>WordsAPI includes synonyms, antonyms, similar words, hierarchical information and more!</b>
<b>Directions: </b><br><ol>
<li>Register for a free API key at <a href='https://rapidapi.com/auth/sign-up' target='_blank'>rapidapi.com</a> (2600 calls a month)</li>
<li>You will get different word analysis types depending on the word. Not all words will return a result for all APIs</li>
<li>Input a singular word into the field below</li>
</ol>
""", unsafe_allow_html=True)
Now we build our app form which asks the user to input their word they want to be analyzed and their RapidAPI API key. When the user hits the submit button the app starts processing the API calls.
form = st.form(key='appform')
word = form.text_input('Enter a singular word')
apikey = form.text_input('Enter your RapidAPI key')
submit = form.form_submit_button(label='Run API')
if submit:
headers = {
'x-rapidapi-key': apikey,
'x-rapidapi-host': "wordsapiv1.p.rapidapi.com"
}
This next part are all the functions for all the API calls for each word analysis type and displays the results. It’s repetitive so I chucked out the entire thing. We set the API call URL, send the request, store the results, parse the results and display the results. Easy!
def frequency(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/frequency'
response = requests.request("GET", cat_url, headers=headers)
frequency = json.loads(response.text)
try:
st.markdown("""
<h3>Frequency</h3>
<b>Returns zipf, a score indicating how common the word is in the English language, with a range of 1 to 7; perMillion, the number of times the word is likely to appear in a corpus of one million English words; and diversity, a 0-1 scale the shows the likelyhood of the word appearing in an English document that is part of a corpus.</b>
""", unsafe_allow_html=True)
st.write("zipf: " + str(frequency['frequency']['zipf']))
st.write("perMillion: " + str(frequency['frequency']['perMillion']))
st.write("diversity: " + str(frequency['frequency']['diversity']))
except:
st.write(":x: Nothing Found")
def usageOf(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/usageOf'
response = requests.request("GET", cat_url, headers=headers)
usageOf = json.loads(response.text)
try:
st.markdown("""
<h3>Usage Of</h3>
<b>Words that the original word is a domain usage of</b>
""", unsafe_allow_html=True)
st.write(usageOf['usageOf'][0])
except:
st.write(":x: Nothing Found")
def inRegion(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/inRegion'
response = requests.request("GET", cat_url, headers=headers)
inRegion = json.loads(response.text)
try:
st.markdown("""
<h3>In Region</h3>
<b>Geographical areas where the word is used</b>
""", unsafe_allow_html=True)
st.write(inRegion['inRegion'][0])
except:
st.write(":x: Nothing Found")
def pertainsTo(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/pertainsTo'
response = requests.request("GET", cat_url, headers=headers)
pertainsTo = json.loads(response.text)
try:
st.markdown("""
<h3>Pertains To</h3>
<b>Words to which the original word is relevant</b>
""", unsafe_allow_html=True)
st.write(pertainsTo['pertainsTo'][0])
except:
st.write(":x: Nothing Found")
def category(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/inCategory'
response = requests.request("GET", cat_url, headers=headers)
category = json.loads(response.text)
try:
st.markdown("""
<h3>In Category</h3>
<b>The domain category to which the original word belongs</b>
""", unsafe_allow_html=True)
st.write(category['inCategory'][0])
except:
st.write(":x: Nothing Found")
def memberof(word,headers):
memberof_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/memberOf'
response = requests.request("GET", memberof_url, headers=headers)
memberof = json.loads(response.text)
st.markdown("""
<h3>Member Of</h3>
<b>A group to which the word belongs</b>
""", unsafe_allow_html=True)
if len(memberof['memberOf']) != 0:
getall = ""
for x in memberof['memberOf']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def instanceof(word,headers):
memberof_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/instanceOf'
response = requests.request("GET", memberof_url, headers=headers)
instanceof = json.loads(response.text)
st.markdown("""
<h3>Instance Of</h3>
<b>Words that the parameter word is an example of</b>
""", unsafe_allow_html=True)
if len(instanceof['instanceOf']) != 0:
getall = ""
for x in instanceof['instanceOf']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def hasparts(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/hasParts'
response = requests.request("GET", cat_url, headers=headers)
hasParts = json.loads(response.text)
st.markdown("""
<h3>Has Parts</h3>
<b>Words that are parts of the original word</b>
""", unsafe_allow_html=True)
if len(hasParts['hasParts']) != 0:
getall = ""
for x in hasParts['hasParts']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def partof(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/partOf'
response = requests.request("GET", cat_url, headers=headers)
partof = json.loads(response.text)
st.markdown("""
<h3>Part Of</h3>
<b>The larger whole to which the word belongs</b>
""", unsafe_allow_html=True)
if len(partof['partOf']) != 0:
for x in partof['partOf']:
st.write(x)
else:
st.write(":x: Nothing Found")
def regionOf(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/regionOf'
response = requests.request("GET", cat_url, headers=headers)
regionOf = json.loads(response.text)
st.markdown("""
<h3>Region Of</h3>
<b>Words used in the specified geographical area</b>
""", unsafe_allow_html=True)
if len(regionOf['regionOf']) != 0:
getall = ""
for x in regionOf['regionOf']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def hasCategories(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/hasCategories'
response = requests.request("GET", cat_url, headers=headers)
hasCategories = json.loads(response.text)
st.markdown("""
<h3>Has Categories</h3>
<b>Categories of the parameter word</b>
""", unsafe_allow_html=True)
if len(hasCategories['hasCategories']) != 0:
getall = ""
for x in hasCategories['hasCategories']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def hasSubstances(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/hasSubstances'
response = requests.request("GET", cat_url, headers=headers)
hasSubstances = json.loads(response.text)
st.markdown("""
<h3>Has Substances</h3>
<b>Words that are substances of the parameter word</b>
""", unsafe_allow_html=True)
if len(hasSubstances['hasSubstances']) != 0:
getall = ""
for x in hasSubstances['hasSubstances']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def substanceOf(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/substanceOf'
response = requests.request("GET", cat_url, headers=headers)
substanceOf = json.loads(response.text)
st.markdown("""
<h3>Substance Of</h3>
<b>Substances to which the original word is a part of</b>
""", unsafe_allow_html=True)
if len(substanceOf['substanceOf']) != 0:
getall = ""
for x in substanceOf['substanceOf']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def hasMembers(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/hasMembers'
response = requests.request("GET", cat_url, headers=headers)
hasMembers = json.loads(response.text)
st.markdown("""
<h3>Has Members</h3>
<b>Words that belong to the group defined by the parameter word</b>
""", unsafe_allow_html=True)
if len(hasMembers['hasMembers']) != 0:
getall = ""
for x in hasMembers['hasMembers']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def also(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/also'
response = requests.request("GET", cat_url, headers=headers)
also = json.loads(response.text)
st.markdown("""
<h3>Also</h3>
<b>Phrases of which the word is a part</b>
""", unsafe_allow_html=True)
if len(also['also']) != 0:
getall = ""
for x in also['also']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def similarTo(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/similarTo'
response = requests.request("GET", cat_url, headers=headers)
similarTo = json.loads(response.text)
st.markdown("""
<h3>Similar To</h3>
<b>Words that similar to the original word, but are not synonyms</b>
""", unsafe_allow_html=True)
if len(similarTo['similarTo']) != 0:
getall = ""
for x in similarTo['similarTo']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def hasTypes(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/hasTypes'
response = requests.request("GET", cat_url, headers=headers)
hasTypes = json.loads(response.text)
st.markdown("""
<h3>Has Types</h3>
<b>More specific examples of types of this word</b>
""", unsafe_allow_html=True)
if len(hasTypes['hasTypes']) != 0:
getall = ""
for x in hasTypes['hasTypes']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def typeOf(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/typeOf'
response = requests.request("GET", cat_url, headers=headers)
typeOf = json.loads(response.text)
st.markdown("""
<h3>Type Of</h3>
<b>Words that are more general than the given word</b>
""", unsafe_allow_html=True)
if len(typeOf['typeOf']) != 0:
getall = ""
for x in typeOf['typeOf']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def antonyms(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/antonyms'
response = requests.request("GET", cat_url, headers=headers)
antonyms = json.loads(response.text)
st.markdown("""
<h3>Antonyms</h3>
<b>Antonyms of the word</b>
""", unsafe_allow_html=True)
if len(antonyms['antonyms']) != 0:
getall = ""
for x in antonyms['antonyms']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def rhymes(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/rhymes'
response = requests.request("GET", cat_url, headers=headers)
rhymes = json.loads(response.text)
st.markdown("""
<h3>Rhymes</h3>
<b>Rhymes of the word</b>
""", unsafe_allow_html=True)
if len(rhymes['rhymes']['all']) != 0:
getall = ""
for x in rhymes['rhymes']['all']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def examples(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/examples'
response = requests.request("GET", cat_url, headers=headers)
examples = json.loads(response.text)
st.markdown("""
<h3>Examples</h3>
<b>Examples of the word</b>
""", unsafe_allow_html=True)
if len(examples['examples']) != 0:
getall = ""
for x in examples['examples']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
def synonyms(word,headers):
cat_url = f'https://wordsapiv1.p.rapidapi.com/words/{word}/synonyms'
response = requests.request("GET", cat_url, headers=headers)
synonyms = json.loads(response.text)
st.markdown("""
<h3>Synonyms</h3>
<b>Synonyms of the word</b>
""", unsafe_allow_html=True)
if len(synonyms['synonyms']) != 0:
getall = ""
for x in synonyms['synonyms']:
getall += x + "<br>"
comp.html(getall,500,200,True)
else:
st.write(":x: Nothing Found")
Finally we just simply call all of our functions to process all the API calls for the various word data. Simple!
category(word,headers)
memberof(word,headers)
instanceof(word,headers)
hasparts(word,headers)
partof(word,headers)
pertainsTo(word,headers)
regionOf(word,headers)
inRegion(word,headers)
usageOf(word,headers)
hasCategories(word,headers)
hasSubstances(word,headers)
substanceOf(word,headers)
hasMembers(word,headers)
also(word,headers)
similarTo(word,headers)
hasTypes(word,headers)
typeOf(word,headers)
frequency(word,headers)
antonyms(word,headers)
rhymes(word,headers)
examples(word,headers)
synonyms(word,headers)
st.write('Author: [Greg Bernhardt](https://twitter.com/GregBernhardt4) | Friends: [Rocket Clicks](https://www.rocketclicks.com), [importSEM](https://importsem.com) and [Physics Forums](https://www.physicsforums.com)')
App Complete!
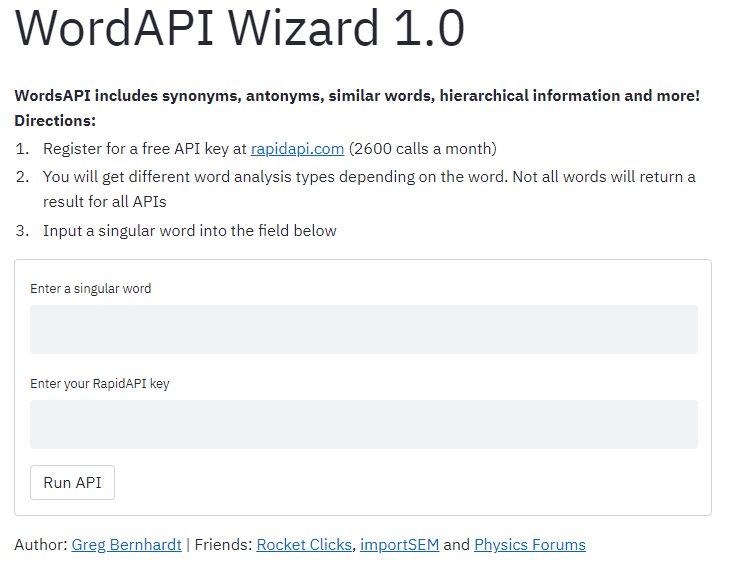
Test out the WordsAPI Wizard app here!
For Streamlit help and resources follow: Charly Wargnier and Fanilo Andrianasolo
Now get out there and try it out! Follow me on Twitter and let me know your applications and ideas!
WordsAPI FAQ

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024











