Find Keyword Opportunities with Google Trends, Python and Ahrefs
Google Trends has long been a powerful tool for SEOs. Understanding past, present, and emerging trends helps reveal seasonality and major events such as the coronavirus pandemic. Who back in 2019 would have thought that toilet paper would hit 100 on Google Trends in March 2020? The Google Trends web interface is user-friendly and reveals a lot, but it provides data separate from your site’s ranking data. What if you could combine ranking data to find which URLs rank for trending keywords? Those would be opportunities to act on now or forecast for later. Let’s dive in!
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax is understood (Pandas experience recommended)
- Access to a Linux environment (I recommend Ubuntu) or Google Colab
- An Ahrefs account (subscription required)
Download Ahrefs keyword data
- Log in to ahrefs.com
- Click “Organic Keywords” on the left sidebar
- Click “Export” at the top right of the data table
- Choose “Full Report” and select UTF-8 format
- Rename the downloaded CSV to ranking.csv
Starting the Script
I recommend developing this script in Google Colab because it uses a Colab-specific library and extension. It can be run elsewhere with minor tweaks.
First, install the module pytrends to access Google Trends data. In Colab, prefix pip3 with an exclamation mark (!pip3).
pip3 install pytrends
Next, import the required modules. pytrends communicates with Google Trends. The data returned by pytrends is partly JSON and partly a pandas DataFrame, so we use pandas to handle it. time provides script delays to reduce request frequency to Google Trends. data_table is a Colab extension that enhances DataFrame visuals; omit it if you are not using Colab.
from pytrends.request import TrendReq import pandas as pd import time from google.colab import data_table
If you run this in Google Colab, load the data table extension to view DataFrames in a spreadsheet-like format.
%load_ext google.colab.data_table
Assign Keyword and Load Ahrefs Data
Create a variable to store the keyword to search in Google Trends.
keyword = "dog collar"
Load the Ahrefs CSV into a pandas DataFrame named rankdf. In Colab, upload the file from the left sidebar. Then drop all columns except Keyword and URL so rankdf contains only those two columns.
rankdf = pd.read_csv('ranking.csv')
rankdf.drop(['#', 'Position History','Position History Date','Volume','Difficulty','Traffic (desc)','CPC','Last Update','Page URL inside','SERP Features'], axis=1, inplace=True)
Configure pytrends Module
It’s time to use the pytrends module. First, call TrendReq() to create a pytrends object. Then build kw_list (it must be a list—even a single item) and call build_payload to request data. You can extend kw_list to include multiple keywords if desired. Finally, build the request to send to Google Trends.
pytrends = TrendReq(hl='en-US', tz=360) kw_list = [] kw_list.append(keyword) pytrends.build_payload(kw_list, cat=0, timeframe='today 5-y', geo='', gprop='')
Access Related Topics for our Keyword
Now access different data types; full documentation is here. This script extracts Related Topics and Related Queries. For Related Topics we pull formattedValue (the breakout percentage), topic_title (the related keyword), and topic_type (the entity category).
We extract these fields from the gettopics object and convert them to lists.
Wrap the data assignments in a try/except because if Google Trends returns no data for the requested word (for example, for an uncommon or invalid term), the module will raise an error. We assign a flag variable to indicate when no data is available and use it later.
gettopics = pytrends.related_topics() stop = 0 try: breakout = list(gettopics.values())[0]['rising']['formattedValue'] title = list(gettopics.values())[0]['rising']['topic_title'] topic = list(gettopics.values())[0]['rising']['topic_type'] except: stop = 1
pytrends is an unofficial API, so there are no official rate limits. Excessive requests can lead to Google blocking you. Timeouts may occur; if so, wait a few seconds and retry. To reduce request frequency, add delays using the time module.
Access Related Queries for our Keyword
We already have Related Topics data; now get the Related Queries data. The process is similar. We want both Top Queries and Rising Queries. We capture both here, but later you will choose either top or rising to match against your Ahrefs CSV.
time.sleep(1) getqueries = pytrends.related_queries() try: top = list(getqueries.values())[0]['top']['query'] rising = list(getqueries.values())[0]['rising']['query'] except: stop = 1
At this point we have the data; we just need to form the final DataFrame. Start by checking if stop == 1; if so, print a message that the keyword lacked enough data. Next, bundle the lists into the variable data. You will notice I omit rising—you must choose either top or rising to use because this script matches a single trends column to the Ahrefs keyword column. Handling both columns in a single match would require additional merging logic.
Merge Lists and Create a Master Dataframe
Create a DataFrame from the master list data and name the columns.
if stop == 1:
print("No Top or Rising Trends Found. Try a diferent keyword")
data = list(zip(breakout,title,topic,top))
trendsdf = pd.DataFrame(data, columns = ['Breakout %','Related Keyword','Entity Label','Top Queries'])
Merge Google Trends and Ahrefs Dataframes
Now merge the Google Trends DataFrame with the Ahrefs DataFrame using the Ahrefs Keyword column to match the Top Queries (or Rising) column from trends. Use fillna() to replace any NaN values with a clear double hyphen (–).
After the merge, the Ahrefs Keyword column will be a duplicate of Top Queries (or Rising), so drop it from the DataFrame.
mergedf = pd.merge(trendsdf, rankdf, left_on='Top Queries', right_on='Keyword', how='left').fillna(value='--') mergedf.drop(['Keyword'], axis=1, inplace=True)
We’re at the last step.
Finally, print the keyword and display the final DataFrame using the Colab data_table extension. Adjust num_rows_per_page (Google usually returns 15–20 rows) and set include_index=True to show row numbers. If not using Colab, use the alternative code below.
print("For Keyword: " + kw_list[0])
data_table.DataTable(mergedf, include_index=False, num_rows_per_page=20)
Final Step Alternative
Adjust the number in head() to change how many rows are displayed.
print("For Keyword: " + kw_list[0])
mergedf.head(20)
Below is an example output using a pet store’s Ahrefs data and the keyword “dog collar”. The colored sections group related columns; they don’t cross-relate beyond being generated from the same keyword.
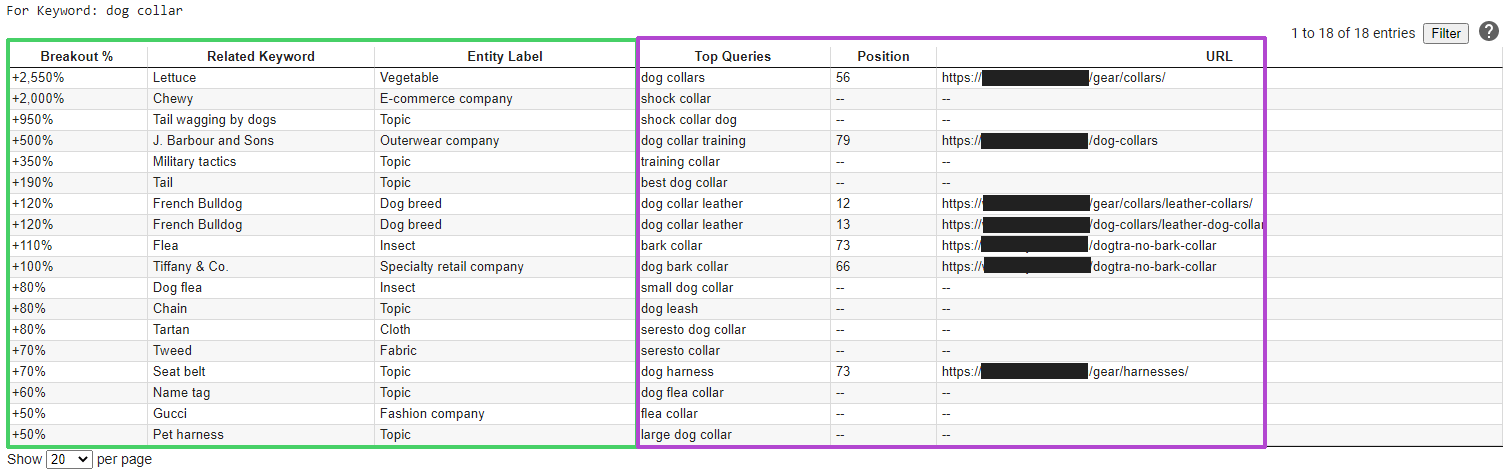
Click to enlarge
Conclusion
Google Trends is a powerful tool for exploring historical trends and forecasting. Accessing Trends programmatically opens many possibilities. This tutorial showed a small example of what’s possible. You can extend it to multiple keywords, store results in a database, blend other data sources, or query other Trends endpoints. Try it out, and share your ideas on Twitter!
Google Trends Keyword Research FAQ
How can I identify keyword opportunities using Google Trends, Python, and Ahrefs?
Leverage Python scripts to integrate Ahrefs and Google Trends APIs, automating the process of gathering keyword-related data.
What data can I gather from Ahrefs and Google Trends APIs for keyword analysis?
Both APIs provide valuable insights, offering data on keyword search volume, trends over time, and Ahrefs’ additional metrics like keyword difficulty and search volume.
Is authentication required for accessing Ahrefs API?
Yes, authentication is necessary. Ensure you have the required API key to authenticate and access Ahrefs’ data programmatically.
How do I handle file uploads when submitting a Gravity Form via the API with Python?
To handle file uploads, include the file data in the API request payload and confirm that your form and WordPress site are configured to support file uploads.
Where can I find detailed guidance and examples for using Python with Ahrefs and Google Trends for keyword analysis?
Refer to the documentation provided by Ahrefs and Google Trends for comprehensive guidance, examples, and best practices when implementing Python scripts for keyword analysis.

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024