
Compare Keyword SERP Similarity in Bulk with Python
Studying search engine results pages (SERPs) is one of SEO’s oldest and still best methods for understanding keywords and how Google treats them. When conducting keyword research, we often end up with a large list of candidates. Then we must validate and clean that list. Cleaning matters because items that appear to be unique opportunities can actually be duplicative, synonymous, or topically similar enough that we should consolidate them to avoid cannibalization.
Additionally, this understanding helps identify words to include on the pages you are researching. It can also serve as the starting point for clustering keywords by similarity, though clustering requires additional logic to be useful.
Over the past few years, SERP comparison tools have gained traction. Recently, Ahrefs released a SERP comparison tool and Keyword Insights now allows deep SERP analysis for three keywords at a time. These are sophisticated SEO products, but what if you want a tool that can compare more than three keywords? It turns out that’s straightforward to build. This article starts that framework, which you can extend with additional logic and sophistication to suit your needs.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax is understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab
- SERPApi or a similar service like Value SERP (you will need to modify API calls and response handling if not using SERPApi)
- Be careful when copying code, as indentation may not be preserved
Install Modules
The two modules likely required are the SERPapi client (google-search-results) and tldextract. If you are in a notebook, remember the leading exclamation mark.
pip3 install google-search-results
pip3 install tldextract
Import Modules
- requests: for calling APIs
- pandas: storing result data
- serpapi: interfacing with the SERPApi API
- difflib: for calculating percentage differences when comparing lists
- tldextract: easy extraction of domains from links
- seaborn: simple conditional formatting for tables
import pandas as pd import requests from serpapi import GoogleSearch import difflib import tldextract import seaborn as sns
Calculate SERP Difference Percentages
Here we create the first of three functions the main script will execute. This function takes the list of domains or URLs from the SERP for each keyword and compares each list to the others (but not to itself). For each comparison, we use the difflib module to compute a difference ratio for those two lists; list order does not affect the result. Once a keyword’s SERP result set has been compared with every other result set in the group, the difference ratios are averaged, rounded, and recorded. These averages are then multiplied by 100 to produce integer percentages (for example, a returned value of 50% indicates that, on average, half of the domains differ across comparisons).
def get_keyword_serp_diffs(serp_comp):
diffs = []
keyword_diffs = []
serp_comp = serp_comp
for x in serp_comp:
diffs = []
for y in serp_comp:
if x != y:
sm=difflib.SequenceMatcher(None,x,y)
diffs.append(sm.ratio())
try:
keyword_diffs.append(round(sum(diffs)/len(diffs),2))
except:
keyword_diffs.append(1)
keyword_diffs = [int(x*100) for x in keyword_diffs]
return keyword_diffs
Extract Domains From SERP
After obtaining the search results JSON from the API, extract domains from the result links — that’s the primary data we need, not the rankings. The tldextract module simplifies extracting the registered domain from a full URL. If you require a more granular comparison, alter this snippet to include the full URL or domain + path; that yields a finer-grained similarity measure for closely related keywords. Ultimately, the extracted domains or URLs are collected into a list and returned to the main script.
def get_serp_comp(results):
serp_comp = []
for x in results["organic_results"]:
ext = tldextract.extract(x["link"])
domain = ext.domain + '.' + ext.suffix
serp_comp.append(domain)
return serp_comp
Call SERP API
Next, create a function to call SERPAPI and retrieve the SERP JSON for each keyword. Several parameters here can be adjusted for language and location preferences. You can also request more organic results for a larger sample; this example compares only the first page (about 8–9 results). See the SERPApi documentation for additional parameters.
def serp(api_key,query):
params = {
"q": query,
"location": "United States",
"hl": "en",
"gl": "us",
"google_domain": "google.com",
"device": "desktop",
"num": "9",
"api_key": api_key}
search = GoogleSearch(params)
results = search.get_dict()
return results
Loop Through Keywords and Run Functions
Now construct the script loop. Place your keywords in the list above; I recommend limiting it to 20 or fewer, because larger lists can dilute the signal depending on how similar or different the entries are. Always compare topically related keywords.
With the keyword list and SERP API key configured, loop through each keyword and call the serp function to fetch results. Pass those results to get_serp_comp to extract domains or URLs, then pass the lists to get_keyword_serp_diffs to compute similarity scores. Finally, a list comprehension flattens the nested list so it can be inserted into the dataframe.
keywords = ['International Business Machines Corporation','IBM','big blue','International Business Machines','Watson'] serp_comp_keyword_list = [] serp_comp_list = [] api_key = "" for x in keywords: results = serp(api_key,x) serp_comp = get_serp_comp(results) serp_comp_list.append(serp_comp) serp_comp_keyword = get_keyword_serp_diffs(serp_comp_list) serp_comp_keyword_list.append(serp_comp_keyword) serp_comp_keyword_list = [element for sublist in serp_comp_keyword_list for element in sublist]
Inject Data into Dataframe and Display
Finally, create a Pandas dataframe with two columns and populate them with the keywords and the computed similarity scores. Apply a Seaborn color map for quick identification of high-similarity keywords. For longer keyword sets, consider sorting by score.
df = pd.DataFrame(columns = ['Keyword','Keyword SERP Sim'])
df['Keyword'] = keywords
df['Keyword SERP Sim'] = serp_comp_keyword_list
cm = sns.light_palette("green",as_cmap=True)
df2 = df
df2 = df2.style.background_gradient(cmap=cm)
df2
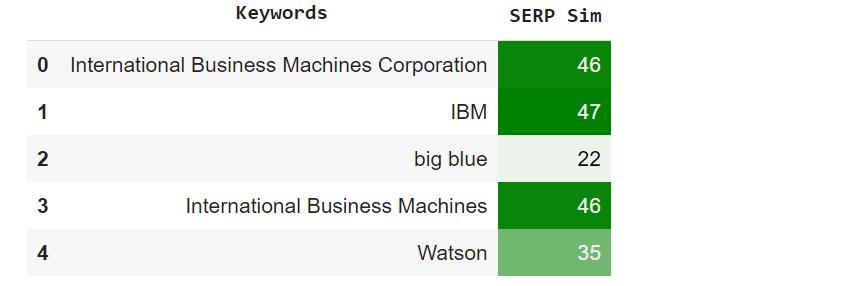
Sample Output
I wanted to see how similar the SERPs were for various names of IBM. The results are unsurprising but confirmatory (SERP Sim is a percentage). The lesson here is that Google treats “big blue” and “Watson” as somewhat more ambiguous; therefore, you can still target these keywords, but provide context using “IBM” or a similar keyword to avoid ambiguity.
Conclusion
You now have a framework for analyzing keyword SERP differences for SEO. Consider extending the script — here are a few ideas:
- Extract and compare by URL, not just domain, for greater granularity
- Pipe in search volume and other metrics
- Use Value SERP instead of SERPApi
- Compare SERP features across keyword SERPs
- Sort the dataframe by score values
If you’re into SERP analysis, see my other tutorial on calculating readability scores.
Now try it out! Follow me on Twitter and let me know your Python SEO applications and ideas.
SERP Similarity FAQ
How can Python be used to compare keyword SERP (Search Engine Results Page) similarity in bulk for SEO analysis?
Python scripts can be developed to fetch and process SERP data for multiple keywords, enabling bulk comparison of SERP similarity and insights into search result variations.
Which Python libraries are commonly used for comparing keyword SERP similarity in bulk?
Commonly used Python libraries for this task include requests for fetching SERP data, beautifulsoup for HTML parsing, and pandas for data manipulation.
What specific steps are involved in using Python to compare keyword SERP similarity in bulk?
The process includes fetching SERP data for selected keywords, preprocessing the data, implementing similarity measures, and using Python to analyze results and generate SEO insights.
Are there any considerations or limitations when using Python for bulk comparison of keyword SERP similarity?
Consider variability in SERP layouts, the choice of similarity metrics, and the need to define clear goals and comparison criteria. Analyses may require regular updates to remain accurate.
Where can I find examples and documentation for comparing keyword SERP similarity with Python?
Explore online tutorials, documentation for relevant Python libraries, and SEO-specific resources for practical examples and detailed guides on using Python to compare keyword SERP similarity in bulk.

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024
Related Python Tutorials
- Calculate Similarity Between Article Elements Using spaCy

- Create a Topical Internal Link Graph for SEO with NetworkX and Python

- Is Python SEO Right For You? Practical Python Advice and FAQ

- Update a Google Sheet with Semrush Position Tracking API Using Python

- Audit URLs for SEO Using ahrefs Backlink API Data





- SEOs Can Retrieve the Google Cache Date for URLs Using Python

- Calculate GSC CTR Stats By Position Using Python for SEO

- Find Interlinking Opps via Entity N-gram Matches Using Python

- Classify Anchor Text N-Grams for Interlinking Insights with Python

- Generate a 404 Redirect List for SEO with Polyfuzz Using Python






