
Use Python Difflib to Detect and Display Robots.txt Changes
Robots.txt is a great tool for SEOs to help control crawling from spiders. It is however a sensitive tool and one where a simple mistake can cause a great deal of damage. When you are working with a team of SEOs or working with a client’s team of developers, there is a risk of someone tinkering where they shouldn’t be or perhaps someone just makes a simple mistake. In any case, the damage can be mitigated if caught early. Catch changes to Robots.txt quickly using the Python tutorial below.
Table of Contents
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu) or Google Colab
Starting the Script
First, we install the fake_useragent module to use in our call header. This can help ward off light abuse detection. Note if you are using Google Colab, put an exclamation mark at the beginning of pip3, so !pip3.
pip3 install fake_useragent
Now we import the needed modules. os is for writing and reading files. requests grab the robotx.txt content. fake_useragent sets the user agent for the request. time sets script delays. difflib compares two pieces of content.
import os import requests from fake_useragent import UserAgent import time import difflib
Assign Variables
First, let’s set some variables. We’ll set a name to use in our file names and a URL for the site where we want to test the robots.txt file. Then we set up the fake user agent, and format the name to replace a space with an underscore in case it exists. We’re going to store the current robots.txt file, past stored robots.txt file, and a changes.html file.
name="pf"
url="https://www.physicsforums.com"
ua = UserAgent()
header = {"user-agent": ua.chrome}
name = name.replace(" ","_")
oldrobots = "old_robots_" + name + ".txt"
newrobots = "new_robots_" + name + ".txt"
changes = "changes_" + name + ".html"
Grab the current robots.txt file
It’s time to request the current robots.txt file and save it locally. It will overwrite the existing file if it exists, making sure the current file on file is always current. Note the backslash in the request. Make sure you don’t have a backslash in your URL variable at the end.
getrobotstxt = requests.get(url + "/robots.txt",headers=header,verify=True) open(newrobots, "wb").write(getrobotstxt.content)
Now let’s open the previously stored robots.txt file if it exists. If you haven’t run this with the site yet then it won’t exist and we’ll create it, using the current file and, for the first run, the two will match. Moving forward this script will be useful next time when time has passed and maybe the file has changed.
try: get_old_robotstxt = open(oldrobots,"r") except: open(oldrobots, "wb").write(getrobotstxt.content) time.sleep(1) get_old_robotstxt = open(oldrobots,"r") get_old_robotstxt_contents = get_old_robotstxt.read()
Now we load the current robots.txt file into a variable so we can compare later.
get_new_robotstxt = open(newrobots,"r") get_new_robotstxt_contents = get_new_robotstxt.read()
Compare current robots.txt to old
Let’s compare the two files on a very high level before we do any more processing. At this point, we can also detect any server blocking. I’ve noticed sites using the Apache module ModSecurity will block robots.txt from a non-human detected request. After that, we either print out the robots.txt texts match and the script ends or they don’t match and we continue to process the differences.
blocked = re.search("Security",getrobotstxt.text)
if blocked:
print("blocked by modsecurity")
elif get_old_robotstxt_contents == get_new_robotstxt_contents:
print(name + " Robots.txt Match")
else:
print(name + " Robots.txt don't match")
Next, to compare changes in the files we need to split them into lines, organized in a list. This is so we can compare line 1 current file to line 1 previous file and so forth. From my testing splitlines() function works best if both data sources are the same. So both files are a file or both from a string. Since we store the previous robots.txt data in a file, we also store the current in a file.
try: oldrobot = get_old_robotstxt_contents.splitlines() newrobot = get_new_robotstxt_contents.splitlines() except: oldrobot = "" newrobot = get_new_robotstxt_contents.splitlines()
Finally, we check if there is a difference between the current vs previous file and if so, feed the two files (now broken up into lists by each line) into the difflib.HtmlDiff() function from the difflib module to build the comparison table as an HTML table. We then write that HTML table with some CSS styling (feel free to customize) to an HTML file that you can load in a browser to see the results.
if get_new_robotstxt_contents != get_old_robotstxt_contents:
difftable = difflib.HtmlDiff(wrapcolumn=95).make_table(oldrobot,newrobot)
open(changes, "w").write("<html><head><style>.diff_add{background-color:#cf9}.diff_sub{background-color:#fcf}.diff_next{display:none}.diff_chg{background-color:#fc9}.diff td{overflow-wrap:break-word;font-size:14px;overflow:auto;font-family:Consolas}.diff table{overflow:auto}td.diff_header{width:10px;padding-left:0;padding-right:0;text-align:center;font-weight:700}table{padding:5px}</style></head><body>" + difftable + "</body></html>")
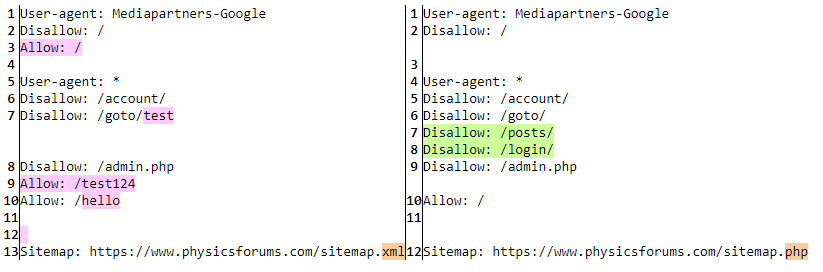
Example Output
Pink = removed
Green = added
Orange = changed
Conclusion
Managing and monitoring your robots.txt file is important and I hope this tutorial has given you a starting point in doing that. You could extend this script by storing the files in a database and setting up an email notification if there is a change. I give examples of how to do each in other tutorials. So get out there and try it out! Follow me on Twitter and let me know your applications and ideas!
For Robots.txt testing using Python, see advertools.
Difflib robots.txt FAQ
How can Python Difflib be used to detect and display changes in robots.txt files?
Leverage Python’s Difflib module to compare different versions of robots.txt files and highlight the changes between them.
Is Difflib suitable for detecting changes in other types of files, or is it specific to robots.txt?
Difflib is versatile and can be applied to detect changes in various types of text files, not limited to robots.txt. It compares sequences of lines and highlights the differences.
Are there specific considerations for using Python Difflib with robots.txt files?
No specific considerations are required. Difflib can be applied to robots.txt files like any other text file, providing insights into modifications made over different versions.
Can Python scripts utilizing Difflib be automated to check for robots.txt changes regularly?
Yes, Python scripts can be automated to regularly check for changes in robots.txt files using Difflib, providing a proactive approach to monitoring and ensuring compliance.
Where can I find examples and documentation for implementing Python Difflib for robots.txt changes?
Explore Python’s official documentation for the Difflib module, and refer to online tutorials and examples that demonstrate how to use Difflib specifically for detecting and displaying changes in robots.txt files.

- Evaluate Subreddit Posts in Bulk Using GPT4 Prompting - December 12, 2024
- Calculate Similarity Between Article Elements Using spaCy - November 13, 2024
- Audit URLs for SEO Using ahrefs Backlink API Data - November 11, 2024




